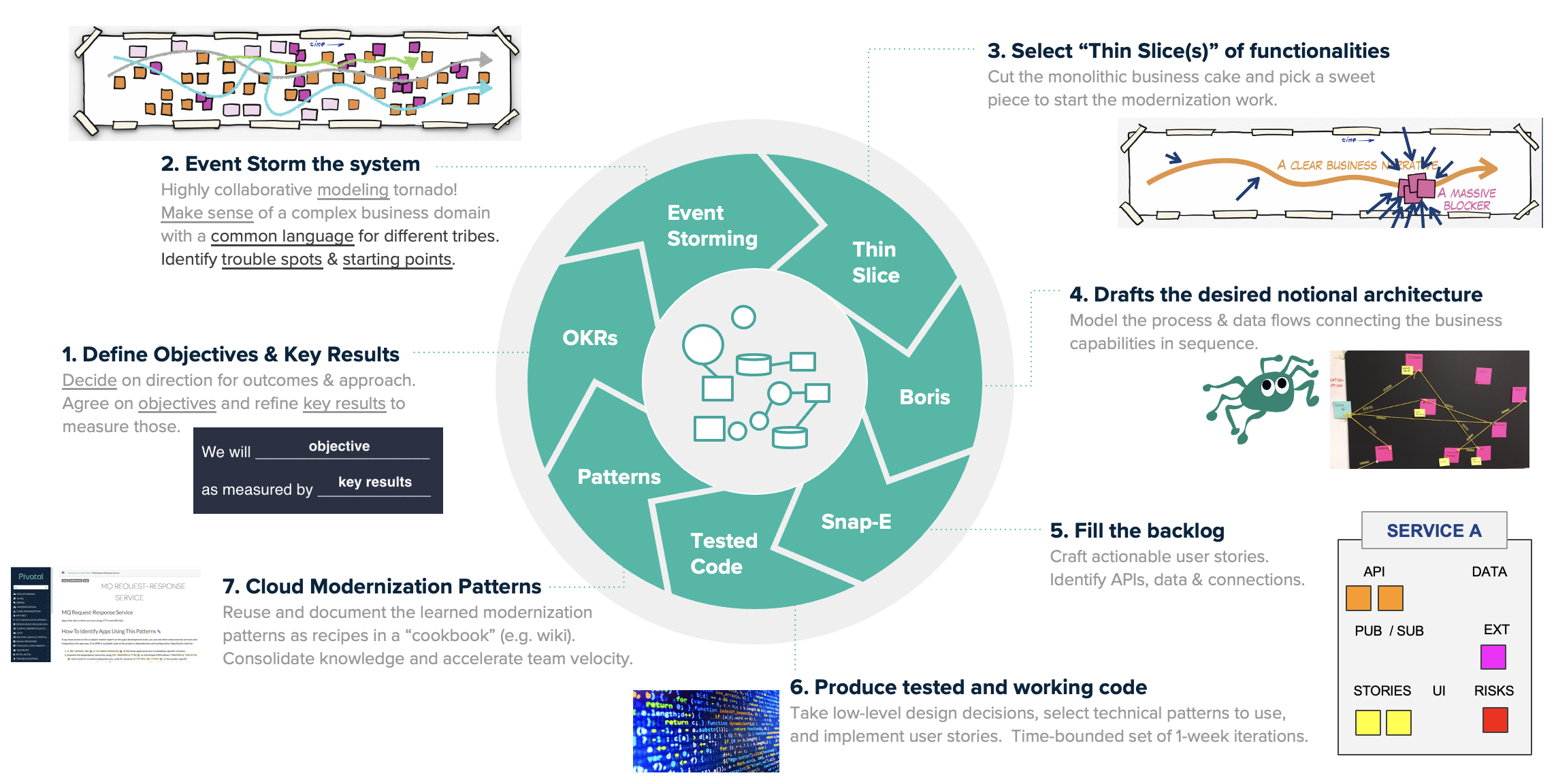
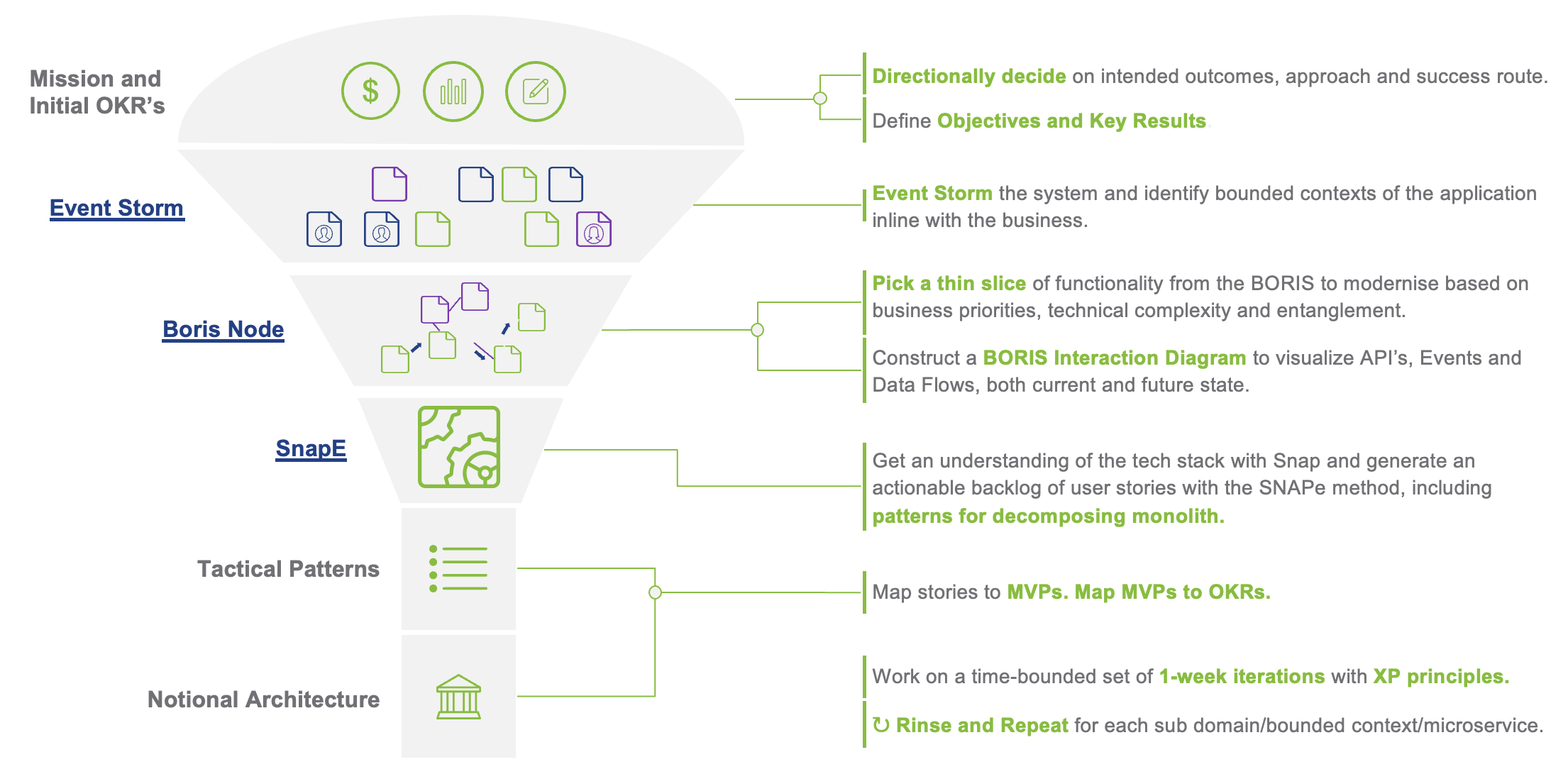
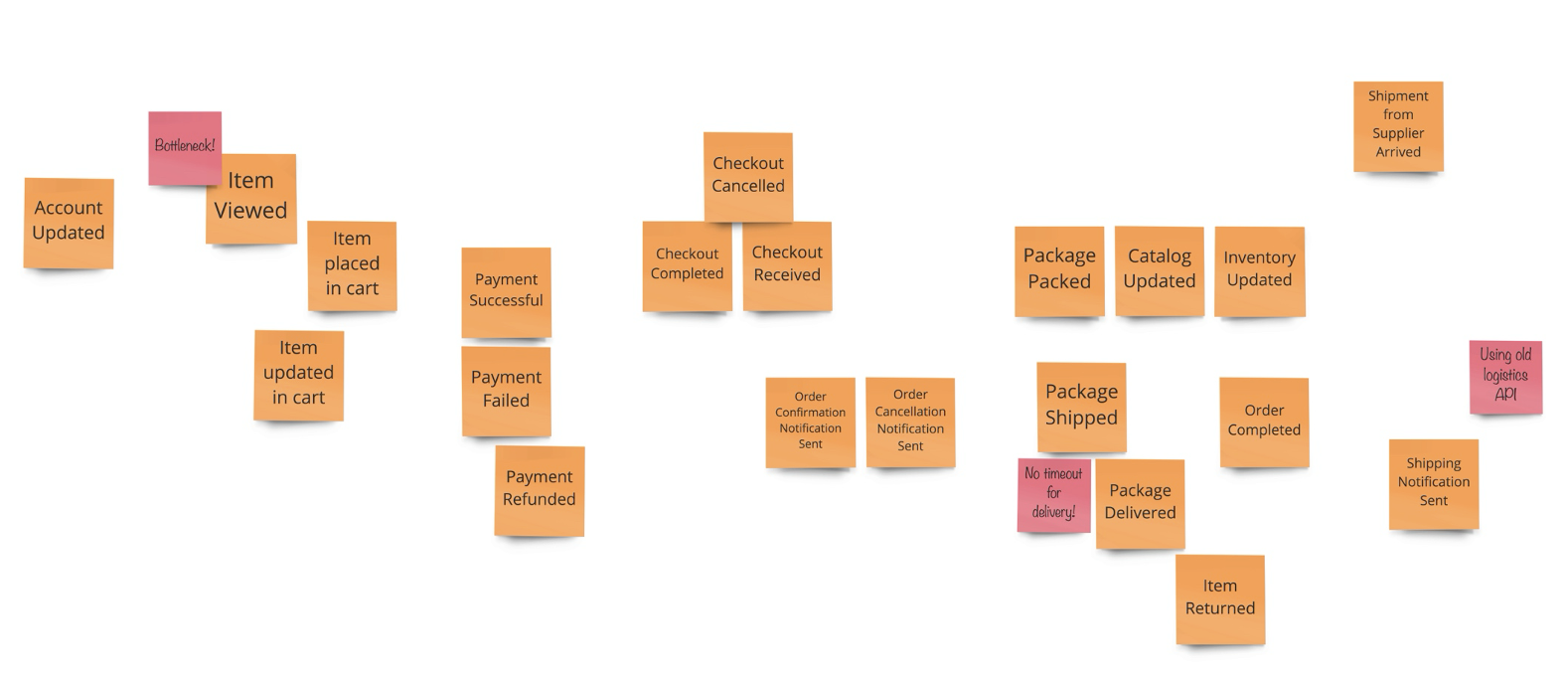
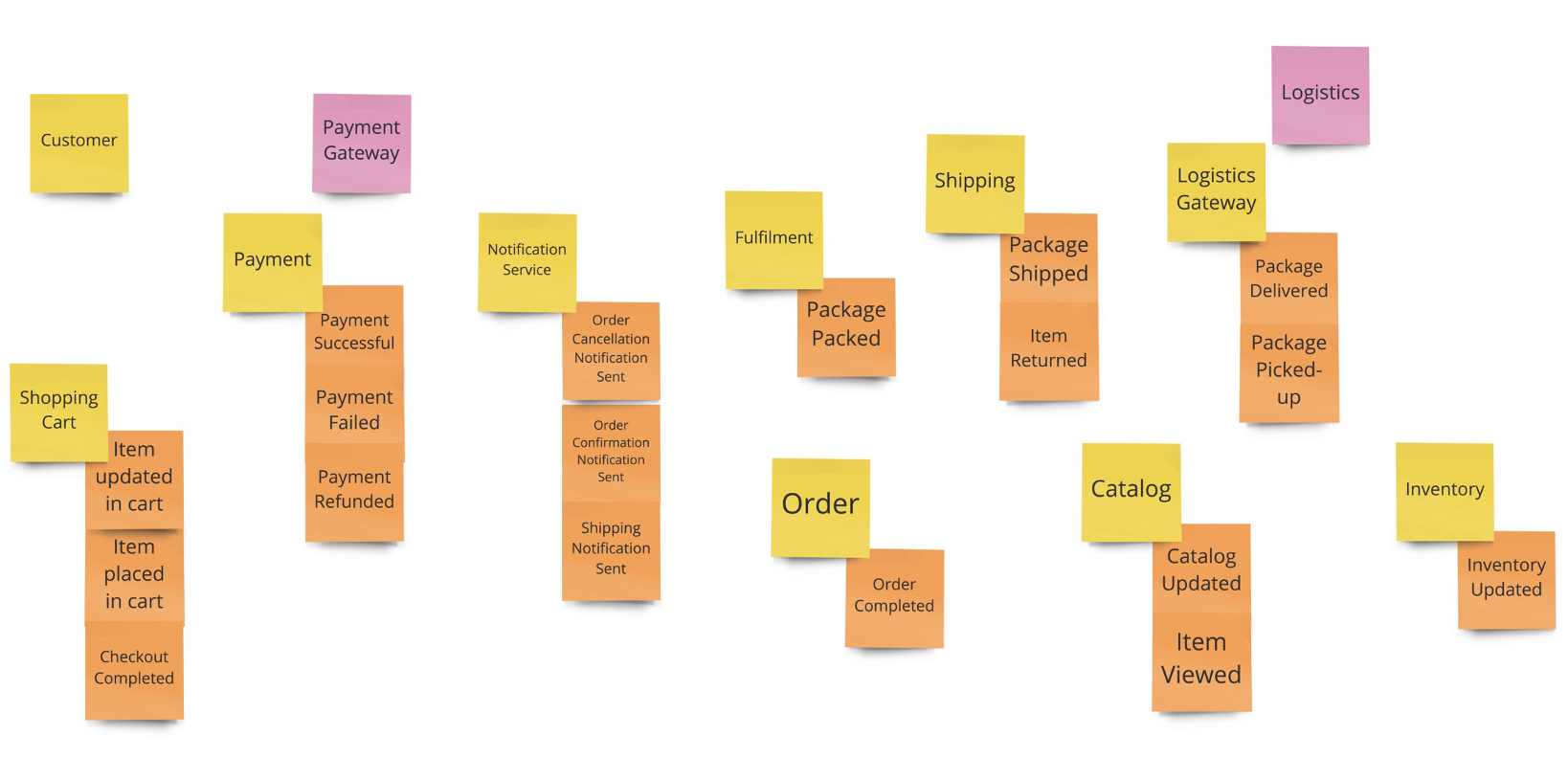
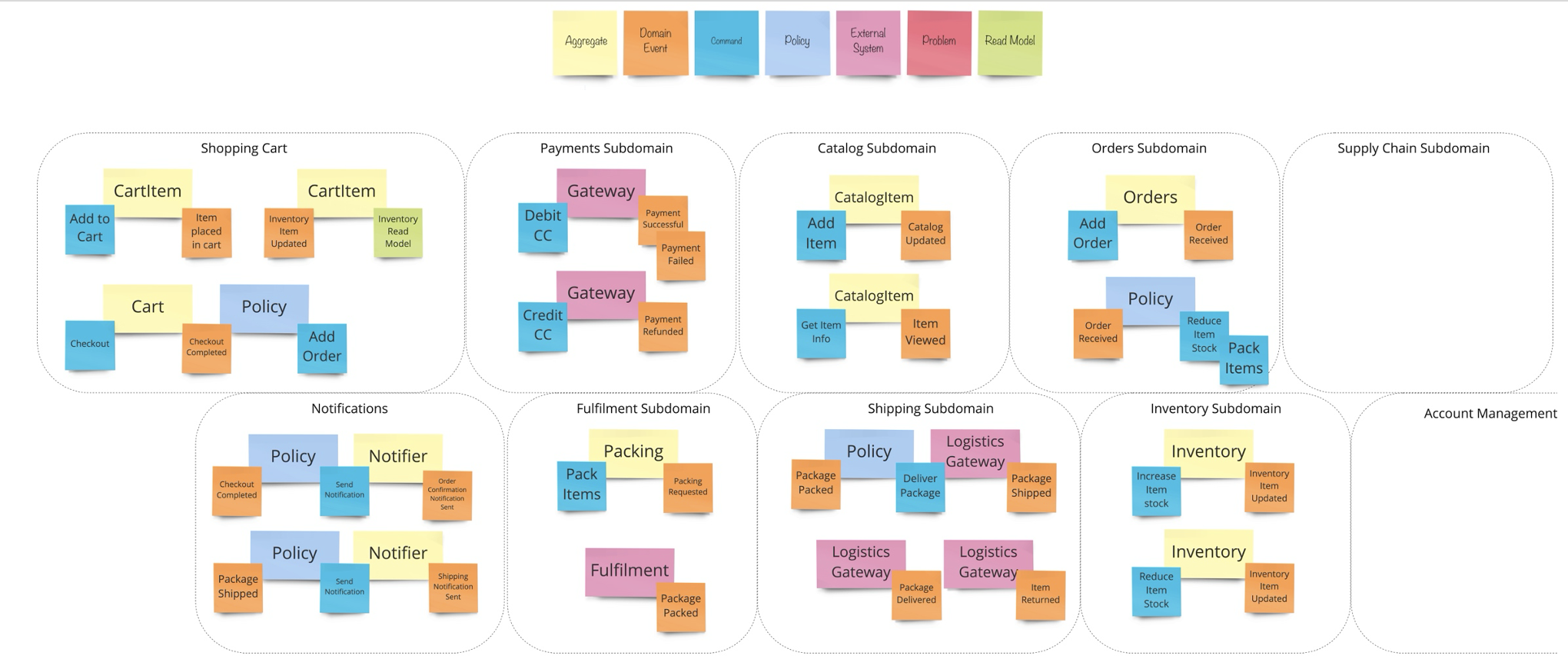
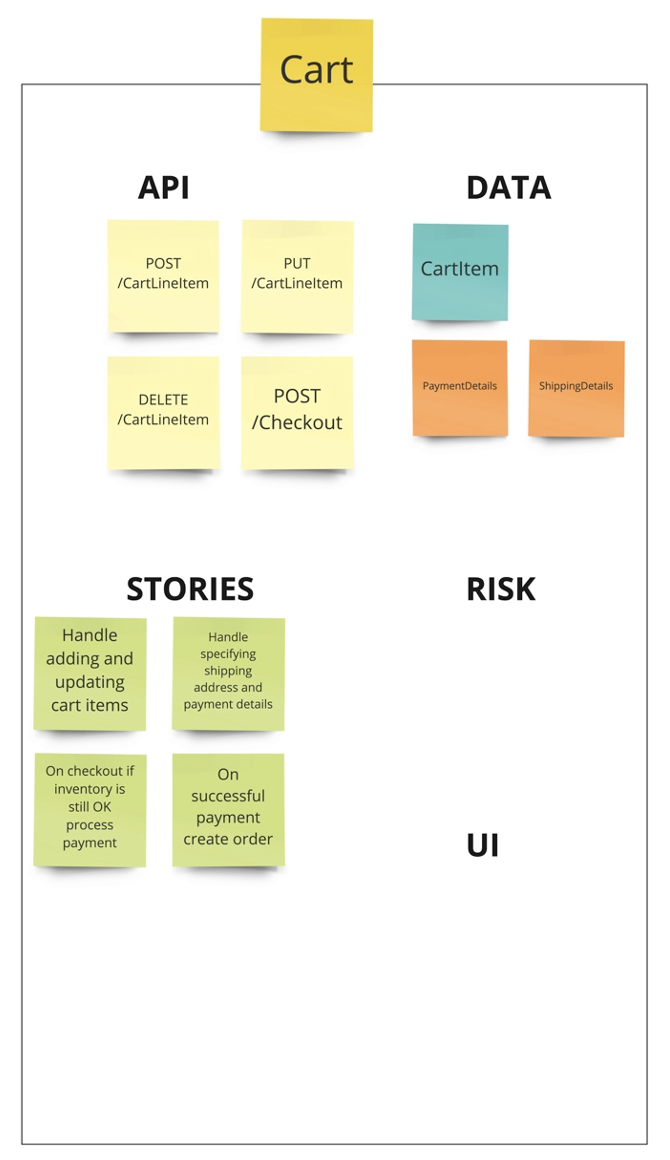
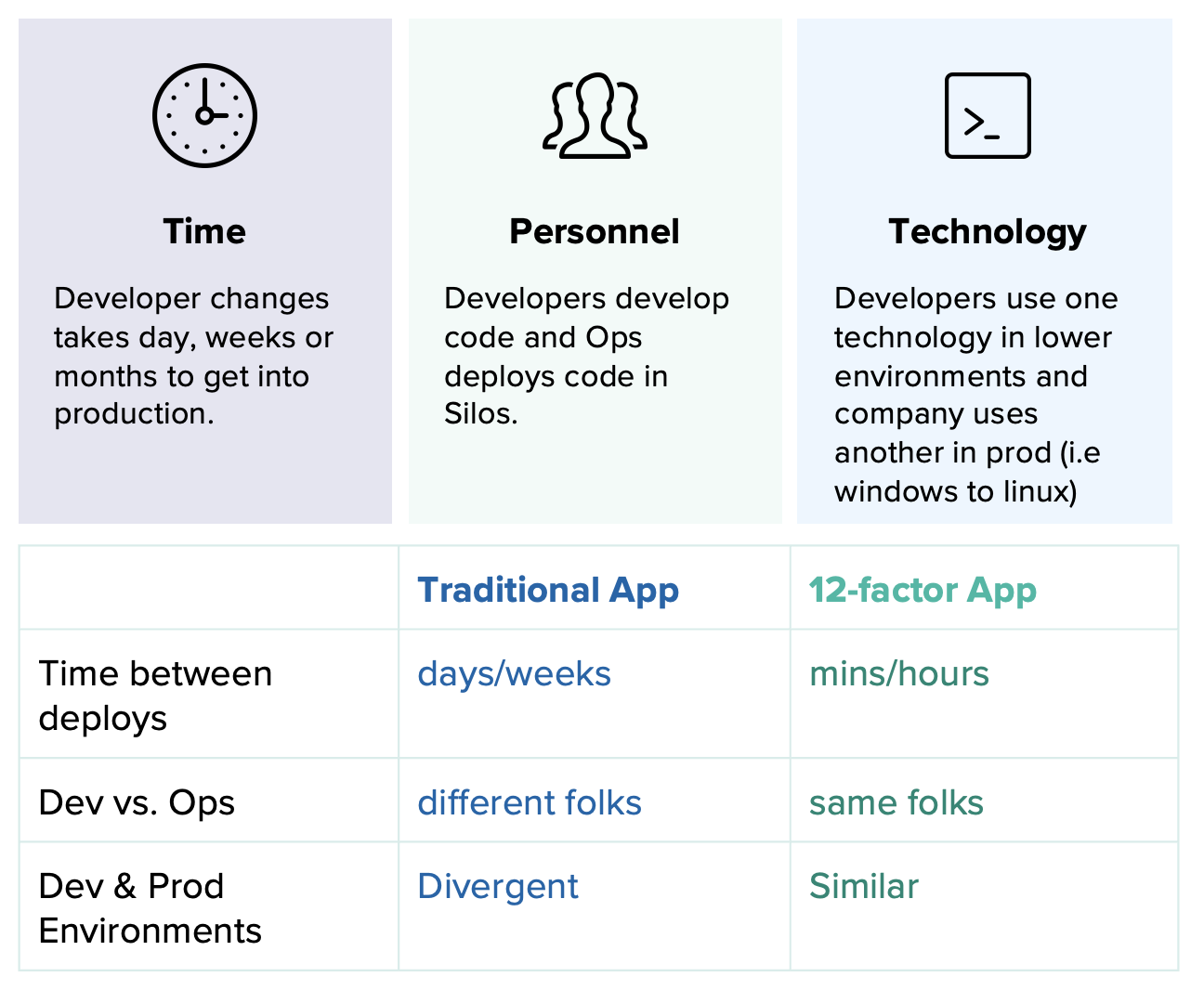
กระบวนการในการพิจารณา เพื่อประเมินความเหมาะสมสำหรับการย้าย Application ไปยัง Cloud Native Platform นั้นมี criteria หลายอย่างด้วยกัน ซึ้งบทความนี้จะให้คำแนะนำเพื่อเป็นแนวทางให้สามารถตรวจสอบ Application จัดลำดับความสำคัญ สิ่งที่ต้องปรับเปลี่ยน (refactore) เพื่อทำเป็น backlog ในขั้นตอนของ Implement ต่อไป
สำหรับการประเมินนั้น หลักๆ จะใช้หลักการของ 12 Factors ที่เป็นหลักการในการออกแบบ Cloud Native Application ซึ้งสามารถอ่านข้อมูลเพิ่มเติมได้จาก http://12factor.net
โดยแต่ละรายการที่จะกล่าวต่อไปในหัวข้อ 12 Factors ที่ส่งผลกระทบกับกระบวนการออกแบบ Application ที่ถ้า Application สามารถ comply ได้ ก็จะจัดได้ว่าเหมาะสมในการย้าย platform (replatform) แต่ถ้ากรณีที่ Factor ที่สำคัญๆ Application ไม่สามารถ comply ได้ก็จะพิจารณาว่าไม่เหมาะสมในการย้าย Application ไปยัง Cloud Native Platform
1. Codebase
ในหนึ่ง Codebase หรือ project ต้องมีระบบ Source Code Management (SCM) เพื่อติดตามและบันทึกประวัติการเปลี่ยนแปลงของ source code รวมถึงการทำ versioning ของ source code ทั้งนี้สามารถ deploy application จาก codebase ไปยัง environment ที่แตกต่างกันได้
โดยทั่วไป Platform จะช่วยให้ทีม Agile Development สามารถทำงานได้ง่าย แต่ความสามารถของ Platform ไม่ได้รวมถึงการ migrate หรือ deploy application ผู้ใช้ยังคงใช้วิธี manual proces หรือ automate ผ่านกระบวนการ CI/CD pipeline สำหรับ application ที่มีกระบวนการ build และ packaging (ควบคุมด้วย CI) ผ่านทางระบบ build system สามารถพิจารณาได้ว่ามีความเหมาะสมในการย้ายไปยัง Cloud แต่ในกรณีที่ไม่มีระบบ build system ก็จะมีความยากและปัญหาจากปัจจัยอื่นๆ ตามมา บางกรณี application อาจจะมี script เพื่อดึง dependencies และจัดการการเข้ากันได้กับระบบข้างเคียง ก็อาจจะพิจารณาได้ว่ามีความเหมาะสมระดับปานกลาง
Application ที่ไม่เข้าข่ายข้างต้นจะถูกพิจารณาว่าไม่มีความเหมาะสมในการย้ายไปยัง Cloud Native Platform อย่างไรก็ตามควรคำนึงถึงความยากในการปรับเปลี่ยน และประโยชน์ที่ได้เมื่อ Applicaiton ทำงานบน Cloud Native Platform ประกอบการพิจารณาด้วย
ตัวอย่างปัญหาที่พบ
Application Code ไม่ได้ถูกจัดการด้วย Source Control
Application Code ถูกจัดการด้วย Source Control แต่ Code กระจายไปยังหลายๆ Repositories หรือ SCM
ไม่มีระบบ CI/CD pipeline ตัวอย่างเช่นไม่มี Build service ที่ถูกจัดการด้วย automate tool เช่น TeamCity, Bamboo, Jenkins หรือ build automation tool อื่นๆ
2. Dependencies
ระบุการใช้ dependencies ใน code ให้ชัดเจนและไม่มีการใช้ code ร่วมกันจากหลายๆ project (isolate)
เป็น Factor ที่จำเป็น ถ้า Application ไม่ได้ระบุ Dependencies ที่จัดเจน หรือมีการใช้ code ร่วมกัน จะทำให้การทำ automate ด้วย CI/CD เฉพาะ Application ทำไม่ได้ เพราะต้องรวม Application อื่นเข้ามาใน Process ด้วย ซึ้งจำเป็นต้องปรับเปลี่ยนค่อนค่างมาก
ตัวอย่าง Application ที่มีการระบุ dependencies ที่ดี ส่วนใหญ่จะจัดการผ่าน tool เช่น Gradle, Maven, Ant, NuGet สำหรับ .NET ก็จะไม่ค่อยมีปัญหาเพราะ tool จะสามารถระบุ dependencies ต่างๆ ที่จำเป็นสำหรับ Application ให้ได้
ตัวอย่างปัญหาที่พบ
Application ไม่สามารถแยก deploy ได้ จำเป็นต้อง deploy application อื่นร่วมด้วยถึงจะสามารถทำงานได้
ไม่ได้ใช้ build หรือ dependencies management system เช่น maven, ant, gradle
Application release เดียวกันทำงานได้เฉพาะบาง environment เนื่องจากไม่พบ dependencies ที่ต้องการใน environment ที่มีปัญหา
.NET Application พึ่ง dependencies จาก Global Assembly Cache (GAC) ส่งผลกับการให้ deploy application ไปยัง environment อื่นมีปัญหาจากการหา dependencies ที่ต้องการไม่พบ
3. Configuration
ให้ Environment จัดการ configuration ของ application
Application จะต้องใช้ configuration จาก environment ตัวอย่างเช่น java application จะเขียน config ใว้ใน properties file โดยเก็บไว้ใน disk ของ environment ซึ้งก็จะไม่เข้ากับคำแนะนำนี้ เช่นเดียวกับ .NET ที่เขียน application config ไว้ใน web.config file
แม้จะเป็นไปได้ว่า configuration สามารถ deploy ร่วมกับ application ซึ้งมองว่าเป็น dependencies เฉพาะของ application ก็จะทำให้ยากมากขึ้นในการจัดการ ทั้งนี้ Application ที่ไม่ได้ดึง configuration มาจาก environment อาจจะสามารถ replatform ได้ขึ้นอยู่กับ configuration ที่เก็บใน properties file หรือสถานที่เก็บอื่นนอก environment
สำหรับ application ที่ไม่ตรงตามข้อแนะนำข้างต้น จำเป็นต้องประมาณการความยากในการ migrate เพื่อมาใช้ environment configuration อาจจะพิจารณาร่วมกับการใช้ Service เพื่อติดต่อกับ backend service (เพิ่มเติมในหัวข้อ Backing service Factor) ทั้งนี้การให้น้ำหนักเรื่องการปรับเปลี่ยน application ให้ตรงตามข้อกำหนด เป็นส่วนหนึ่งที่นำมาใช้ในการลำดับ application ที่เหมาะสมกับการ replaform
ตัวอย่างปัญหาที่พบ
การใช้งาน *.properties file ใน code java
มีการใช้ properties class ใน code java
อ่านข้อมูลจำเพาะต่างๆ ของ environment จาก resource และ files
Configuration ทุกอย่างถูกเก็บใน web.config และไฟล์เกี่ยวข้องอื่นๆ (.NET) เช่นเก็บใน configuration manager และ class object
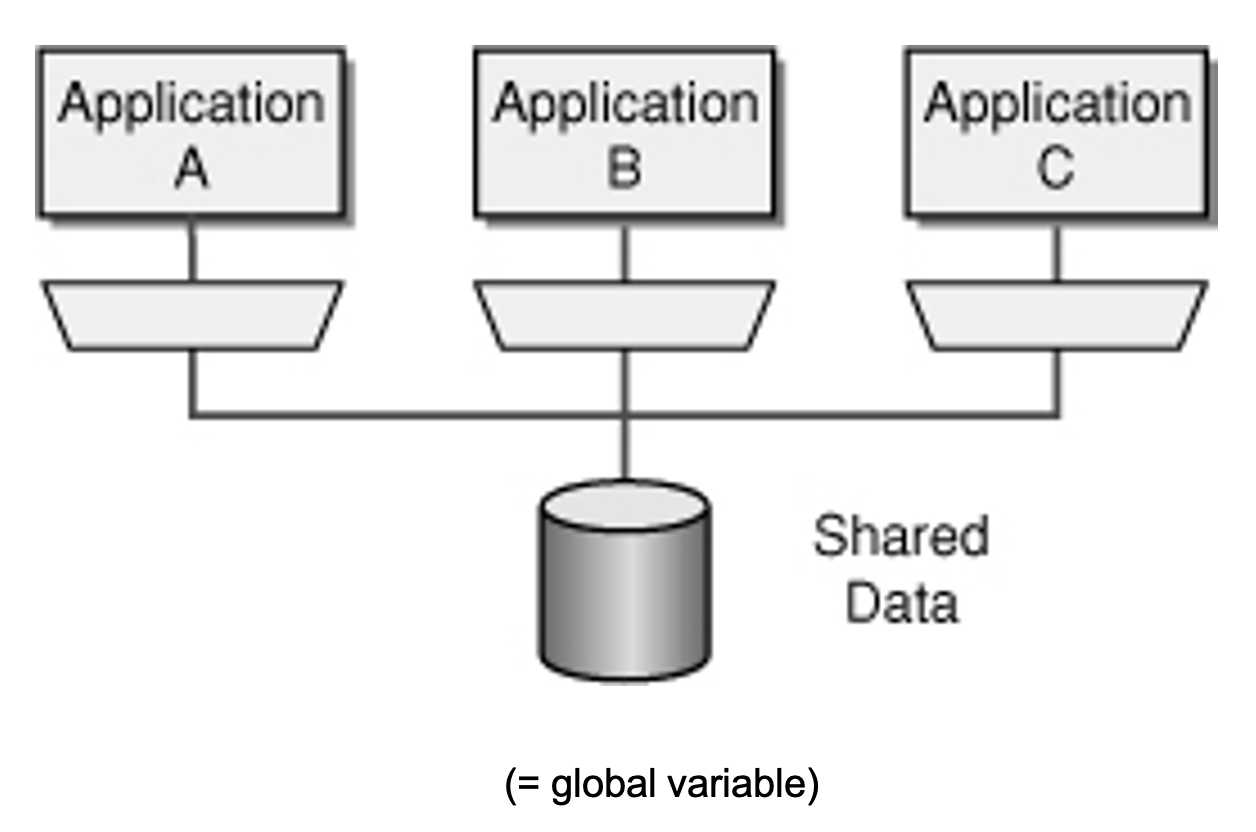
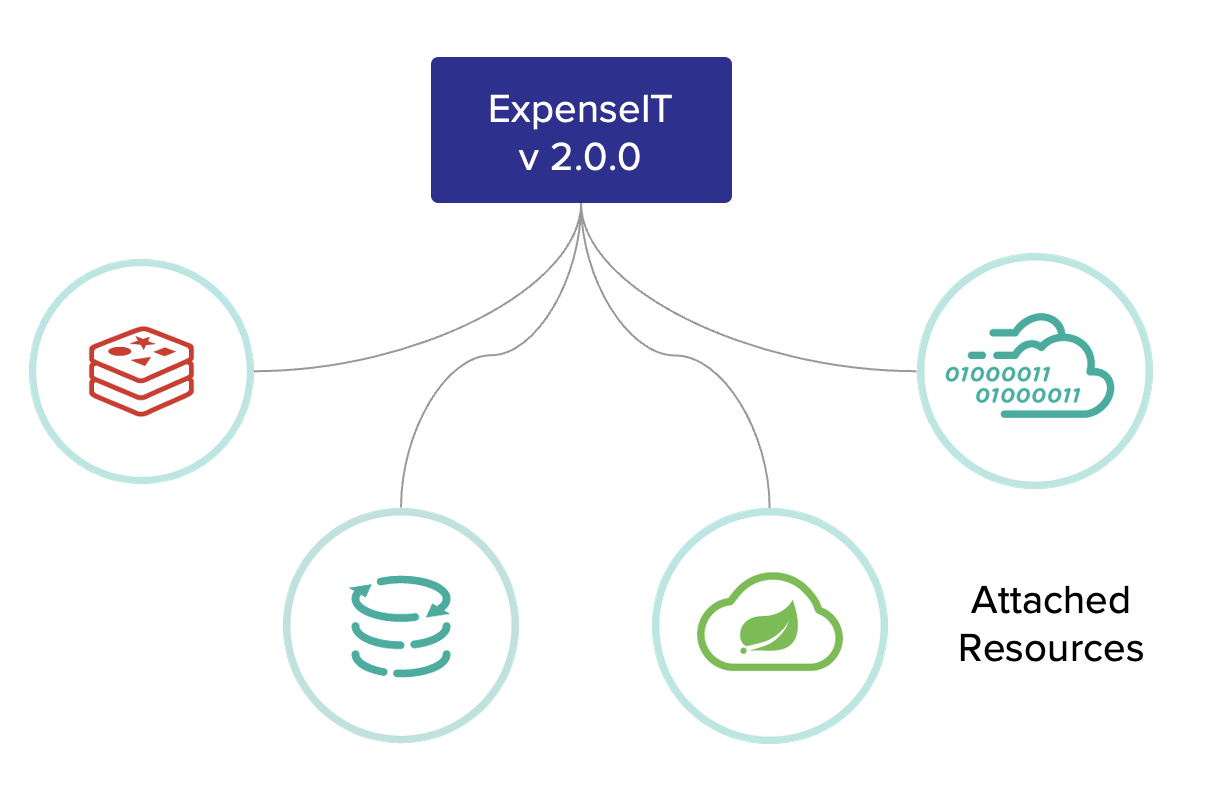
4. Backing Services
ออกแบบให้ services ที่ application ต้องการเรียกใช้ (backing service) เสมือน resource หนึ่งของ application ที่สามารถใช้งานด้วยการนำเข้าและออกได้ง่าย
ตัวอย่างเช่น URL หรือ Locator/Credentials ที่ application ใช้ในการเรียก backing service ถูกเก็บไว้ใน configuration เพื่อให้ถูกต้องตามข้อกำหนดนี้ Application จะต้องทำตามข้อกำหนด Configuration Factor
เพื่อให้เป็นไปตามข้อกำหนด Application ต้องสามารถปรับเปลี่ยนเพื่อใช้ Service (นำเข้า/นำออก) เช่น data store, messing/queueing system, email, caching โดย service พวกนี้จะถูกจัดการผ่านระบบภายนอก (Third party) โดยที่ไม่ส่งผลกระทบกับ application code ทั้งนี้รวมถึง resource ที่สามารถปรับเปลี่ยนได้ในขั้นตอน deployment
ทั้งนี้ Application จะคงสามารถทำงานได้ปกติถึงแม้จะไม่ตรงตามข้อกำหนดโดยขึ้นอยู่กับ Application และ Service ที่เรียกใช้ เช่นกำหนด connection ใน configuration ที่จัดเก็บไว้ใน environment ก็ยังคงถือว่าใช้ได้เหมือนกัน
แนะนำให้แก้ไข code ของ application ที่ไม่ตรงตามข้อกำหนดนี้โดยให้มีการใช้ environment variable เพื่อเรียกใช้ backing service โดยปรับ code ให้ง่ายในการปรับเปลี่ยนมากขึ้น (abstract) เช่นการใช้วิธีการ Dependencies Injection ช่วย ทั้งนี้รวมถึง credentials และ connection parameter สำหรับ legacy application หรือ service ที่ยังไม่ได้อยู่บน cloud environment
ตัวอย่างปัญหาที่พบ
มีการ hard code ค่า configuration (หรือไม่ใช้ environment configuration) เช่น database connection string
กำหนดข้อมูลตายตัวสำหรับค่า URL และ Port สำหรับเชื่อมต่อ backing service
Application เรียกใช้งานได้กับบาง backing service เช่น ทำงานได้เฉพาะ database driver เพราะไม่ได้ใช้ adapters/JDBC/abstractions ช่วย
เก็บ credentials สำหรับ backing service ใน configuration setting ที่อาจมองว่า application ขึ้นอยู่กับ environment มากเกินไป (tight environmental coupling)
Backing services ใน Docker-to-Docker โดยไม่ได้ใช้ Docker image linking จำเป็นต้องพึ่ง /etc/hosts file ที่จะส่งผลเสียกับ platform ตามมาภายหลัง
5. Build, Release, Run
แยกขั้นตอน build และ Run ออกจากกันอย่างชัดเจน
Code ถูกนำไปใช้ในการ deploy ผ่านขั้นตอนหลักๆ อยู่ 3 ขึ้นตอนคือ build , release และก็ run โดยที่ build จะเปลี่ยน code ให้กลายเป็น application ที่สามารถทำงานบน computer ได้ release จะรวมผลลัพธ์จากการ build รวมกับ deployment configuration ที่ application ต้องใช้ในการ deploy และ Run ก็จะ run application บน environment โดยที่ application จะสามารถเข้าถึง configuration ที่ต้องการจาก environment และทำงานเป็น process ในระบบ
ทั้งนี้กระบวนการ CI/CD pipeline จะรวมขั้นตอนข้างต้น เพื่อให้ทำงานสอดคล้องกันในแต่ละขึ้นตอนจากเริ่มจน application สามารถทำงานได้
สิ่งสำคัญที่ต้องพิจารณาคือ ทุกๆ releae จะต้องมีการระบุอย่างชัดเจน เช่นทำ version (uniquely identifiable) สามารถสร้างขึ้นใหม่ได้ (immutable artifact) ส่วนขั้นต้อนการ run จะต้องเล็ก (small) ง่าย (small simple thing) และมีส่วนประกอบที่น้อยที่สุด (few moving part)
ตัวอย่างปัญหาที่พบ
การ deploy จะสำเร็จได้จะต้องอาศัยการตั้งค่าเพื่อติดตั้งบน environment
Application ไม่เป็นไปตามกฏ configuration factor
ไม่สามารถแยกขั้นตอน build, release, run ออกจากกันได้
6. Processes
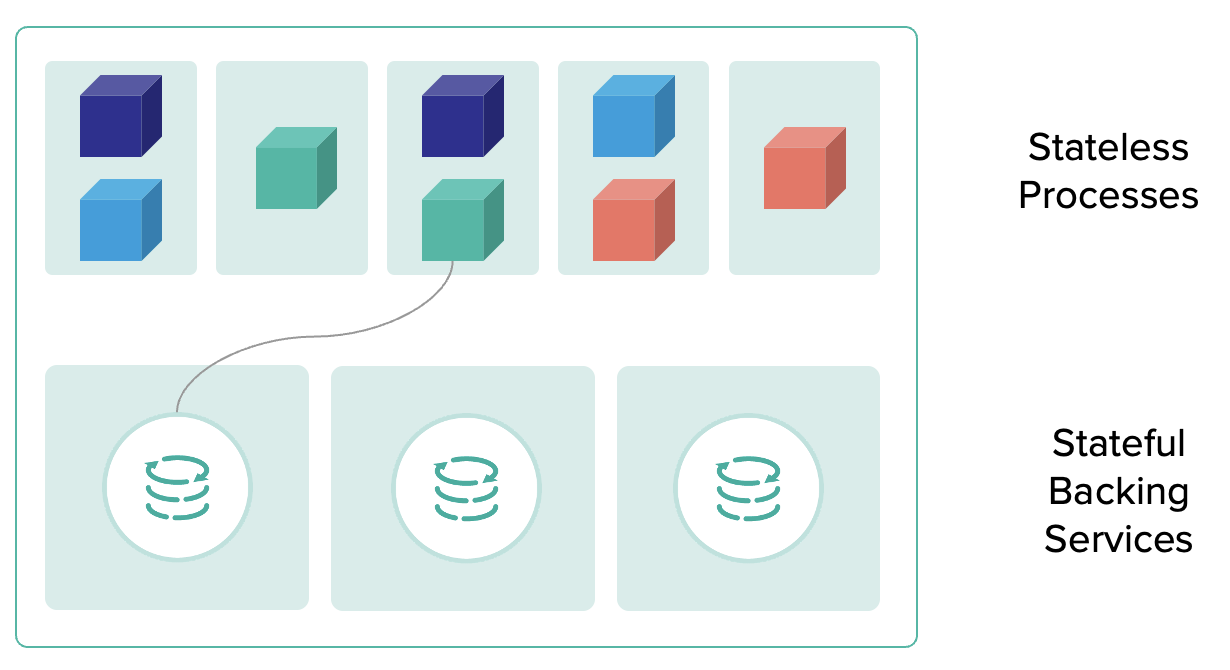
Application ทำงานโดยไม่เก็บ state (Stateless processes) และไม่ share state ให้ process อื่น ในกรณีที่ต้องการเก็บ data จะต้องใช้ backing service ช่วย
File system ที่ให้บริการสำหรับ application ที่ทำงานบน platform จะไม่คงอยู่เสมอไป เป็นไปได้ที่ application ไม่สามารถทำงานได้สำหรับข้อกำหนดนี้คือ file system ถูกลบทิ้งหลังจาก process ของ application จบการทำงาน และไม่สามารถทำงานใหม่ด้วย file system เดิมได้ ดังนั้นการเก็บข้อมูลใดๆ ของ application จะต้องทำผ่าน backingn service (เพิ่มเติมจาก Backing Service Factor)
Application ที่ทำงานได้อย่างมีประสิทธิภาพบน platform จะต้องเป็นในรูปแบบ stateless หมายถึง application จะต้องไม่เก็บ state ใดๆ ไว้ใน memory, local file system หรือ http session state และจะต้องหาแนวทางที่เหมาะสมถ้าในกรณีที่ developer ต้องการเก็บ state ของ application
ในการตรวจสอบ application ว่าเป็นไปตามข้อกำหนดนี้ สามารถทำได้ด้วยวิธีการ “Smoke test” โดย start application ขึ้นมา 2 instance และทำการ rundom request ไปยัง 2 instance เพื่อทดสอบว่า application สามารถทำงานได้ตามปกติ
กรณีที่ใช้ sticky sessions โดยให้ transaction ทำงานที่ process เดียว ก็ถือว่าไม่ตรงตามข้อกำหนดนี้ และไม่ควรเลือกแนวทางนี้ถ้าไม่จำเป็น ในกรณีที่ application ไม่ตรงตามข้อกำหนดนี้ แต่ว่ามี code base ที่สามารถเพิ่มเติมส่วนการจัดการ session ได้ ก็สามารถใช้ session management ในแบบ backing sevice โดยการใช้ Redis ช่วย
การพิจารณาตามข้อกำหนดนี้จะเป็นในมุมของ application process ว่าทำงานอย่างไร รูปแบบการหยุด มีการใช้ state และ process จัดการ state ในระหว่างการทำงานหรือไม่
ตัวอย่างปัญหาที่พบ
Application มีการจัดการ state (รวมถึง session) ใน memory ส่งผลให้ state หาย ทำให้ application ไม่สามารถทำงานใหม่ได้หลังจากถูก terminate
Application แชร์ data ให้กับ application instance อื่น
Application สร้าง data บน file system เพื่อที่จะใช้ต่อเมื่อ process หยุดการทำงาน
Application ทำงานได้จาการใช้ docker data volumes เพื่อที่จะให้ data สามารถเก็บไว้ใช้ได้นอก container process
Application ไม่สามารถทำงานได้เมื่อ start พร้อมกันหลาย instance หรือต้องอาศัย sticky session ช่วย
7. Port Binding
ให้บริการ service ด้วย port ที่ไม่ถูกกำหนดตอนเริ่ม process (runtime injection) ทั้งนี้ web server ต้องให้บริการ service กับผู้ใช้ โดยส่งต่อไปยัง application port ที่ถูกต้อง
บริการที่ไม่ใช่ HTTP Platform จะต้องมีการจัดการ TCP routing เพื่อที่จะสามารถ replatform ได้
ตัวอย่างปัญหาที่พบ
Application ให้บริการผ่าน protocal ที่ไม่ใช่ http วิธีลดปัญหานี้ควรระวังเรื่องการใช้ protocal jmx, multicast, udp, custom tcp protocal, rmi-iiop
มีการระบุ port เป็น requirement เฉพาะ เช่น application จะไม่สามารถ start ได้ถ้าไม่อนุญาติให้ทำงานที่ port 8081
Application ต้องการ process หรือต้องมี port พร้อมใช้งานก่อนถึงทำงานได้
8. Concurrency
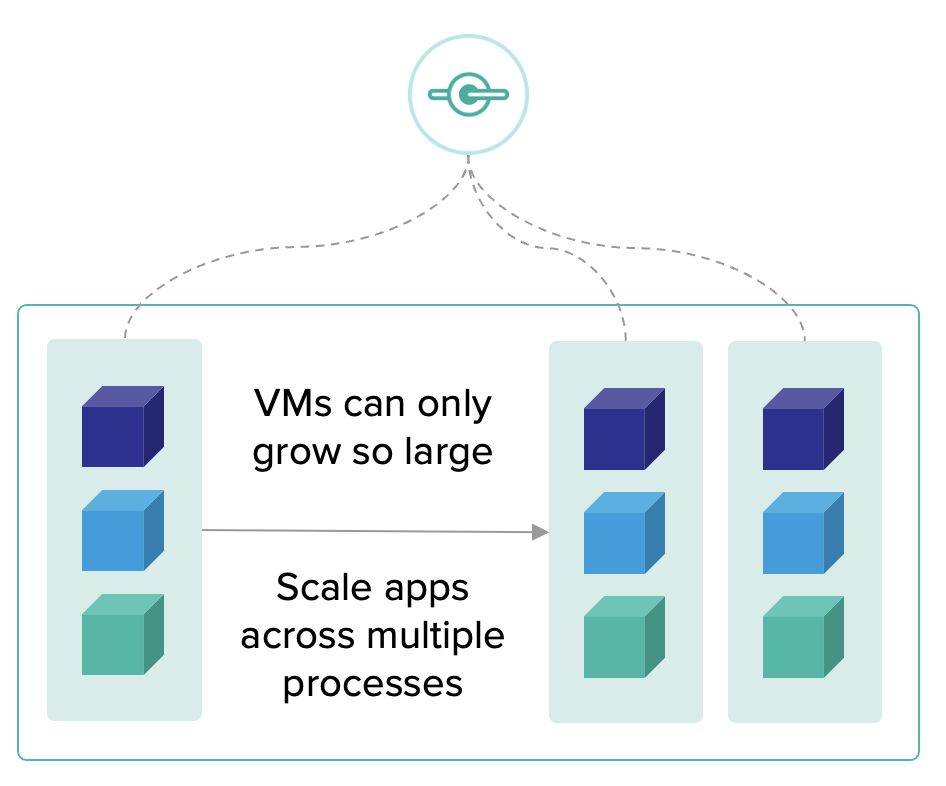
การ scale application เพื่อรองรับการทำงานที่มากขึ้น ด้วยวิธีการเพิ่มจำนวน process
Platform สามารถที่จะ scale application ด้วยการเพิ่มจำนวน instance (scale out) ในขณะที่การเพิ่ม resource เช่น RAM และ CPU (vertical scaling) ก็เป็นอีกทางเลือกแต่จะมีข้อจำกัดเรื่อง hardware
ในการย้าย application ที่เป็นชนิด monolith ขึ้นไปยัง cloud native platform ด้วยวิธีการแก้ปัญหาต่างๆ เพื่อให้สามารถทำงานบน platform ใหม่ได้ เราจะพบว่า monolith application ส่วนใหญ่มีความต้องการ memory มากกว่าทั่วไป เนื่องจากอาจจะต้องจัดการ state ใน application เอง แต่ถ้าสามารถย้ายการจัดการ state ไปยัง backing service ก็จะช่วยเรื่องความต้องการ resource บน platform ที่น้อยลง
ในกรณีที่ application ถูกสร้างตามหลักการ concurrency คือไม่แชร์ resource (share-nothing) สามารถทำงานพร้อมกันหลายน instance ได้ (horizontally partitionable application) การย้ายไปยัง cloud native platform ก็จะสามารถทำได้ง่าย
ตัวอย่างปัญหาที่พบ
Application ไม่สารถทำงานพร้อมๆ กันหลาย instance ได้
การ scale application ให้ทำงานพร้อมกันต้องอาศัย sticky session ในการจัดการ roting ของ request
Application ต้องการ memory จำนวนมากเพื่อที่จะ scale
ใช้หรือพึ่งพาการการกระจาย transaction เพื่อทำงานร่วมกันจากหลาย process (distributed transaction) อาจจะเป็นปัญหาในการ scale (horizontal) บน platform
Application ไม่ตรงตามกฏ configuration factor และ processes factors
Application ถูก deploy ด้วย package ที่เป็น EAR/WAR อาจจะเป็นปัญหากับการ packaging ในรูปแบบ container และการ scale ในแบบเพิ่มจำนวน process
9. Disposability
การเพิ่มความเสถียรด้วยออกแบบให้ appliation เริ่มทำงาน (startup time) และหยุดทำงานอย่างสมบูรณ์ได้เร็ว (graceful shutdown) ทั้งนี้การ start หรือ stop สามารถเกิดขึ้นได้ตลอดเวลาโดยไม่ได้กำหนดล่วงหน้า
ข้อแนะนำนี้ application จะต้องอาศัย ความเร็ว (speed) และความสมบูรณ์ (grace) ทั้งนี้ application จะต้อง shutdown ได้อย่างสมบูรณ์เมื่อได้รับ SIGTERM signal จาก process manager
สำหรับความเร็วนั้น Platform เองสามารถกำหนดได้อย่างเช่น application จะต้องให้บริการทาง port ที่เปิดไว้ภายใน 5 นาที ไม่เช่นนั้น platform จะถือว่า application มีปัญหา หรืออาจจะหยุดการทำงานอย่างสมบูรณ์ไม่ได้ภายในเวลาที่กำหนด ในกรณีนี้ application จะไม่สามารถทำงานบน platform ได้
ตัวอย่างปัญหาที่พบ
Application ใช้เวลามากว่า 5 นาทีเพื่อพร้อมในการทำงาน
Application หยุดการทำงานหลังจากได้ SIGTERM signal ทำให้ข้อมูลหาย หรือทำงานได้ไม่สมบูรณ์
หยุดการทำงาน webserver IIS หรือ terminate process หรือ pool (.NET) ทำให้ข้อมูลหาย หรือทำงานไม่สมบูรณ์
การหยุด application ใช้เวลานาน หรือต้องการขั้นตอนที่ซับซ้อนในการยกเลิกการจอง resource
10. Dev/Prod Parity
ให้การ deploy application และ environment setup ในขั้นตอน development, staging และ production ในรูปแบบเดียวกันให้มากที่สุด เนื่องจาก 12 Factor ถูกออกแบบเพื่อให้ ส่งมอบ application ได้อย่างต่อเนื่อง (continuous deployment) ด้วยการทำให้ความแตกต่างของการ deploy application ในขั้นตอน development มีน้อยที่สุด
ถ้า application ต้องการที่จะต้องปรับแต่งเพื่อให้สามารถทำงานได้บน environment ที่แตกต่างกัน หรือ codebase ต้องมีการแยกเพื่อให้เหมาะสมกับการ deploy ในแต่ละ environment เช่นมี branch QA หรือ PROD อาจจะมองได้ว่าเป็นการ design ที่ไม่ดี และไม่ตรงตามกฏข้างต้น
ในกรณีของ Docker image อาจจะเป็นปัญหากับข้อกำหนดนี้ เพราะอาจจะมีการ pack บาง config เพื่อให้เหมาะสมกับ environment จำเป็นต้องตรวจสอบและป้องกันไม่ให้เกิดปัญหา conflict กับ platform
กรณีที่ application ไม่ตรงตามข้อกำหนดนี้ ก็อาจจะไม่ตรงตาม Backing Service Factor ได้เหมือนกัน เนื่องจากบางกรณี developer จำเป็นต้องใช้ backing service ที่แตกต่างกันระหว่าง development และ production
ตัวอย่างปัญหาที่พบ
มีการใช้ Docker image ที่มีการ pack configuration สำหรับเฉพาะ environment เช่น มีการแยก QA Docker หรือ Prod Docker
การทำงานของ Application แตกต่างกัน หรือ feature ไม่เหมือนกันระหว่าง Production และ Development
เวลาในการ deploy application ใน Dev/QA และ Produciton ค่อนข้างเยอะ จากการที่ต้องปรับแต่ง เพื่อให้ application สามารถทำงานได้ใน environment ที่แตกต่างกัน
11. Logs
จัดการ log ของ application ในแบบเหตุการณ์ที่เกิดต่อเนื่อง (event stream) โดยไม่ควบคุมหรือจัดการไดๆ
Platform มีหน้าที่ต้องจัดการ log ของ application และ system เพื่อแสดงบน console ให้ Developer สามารถเข้าถึงได้ ทั้งนี้ Application เองจะต้องเขียน log ไปยัง standard output และ standard error เพื่อที่ Platform จะสามารถตรวจจับ รวบรวมและแสดงผลได้ในที่เดียว
ดังนั้น application ต้องไม่เขียน log บน file และเก็บไว้ใน file system เอง ในกรณีที่ appliction มีการใช้งาน SLF4j, Log4j, logback หรือ tool อื่นๆ เช่น ELMAH สำหรับ ASP.NET application ที่ ELMAH เองจะต้องการ backing service เช่น SQL server ทั้งนี้การเปลี่ยนให้ application มาใช้ stdout/stderr ก็จะส่งผลกระทบน้อย
Application อาจจะพิจารณาใช้ syslog หรือ log service อื่นๆ เพื่อจัดการเรื่องความปลอดภัยของข้อมูลได้ ในกรณีที่จัดการ stdout/stderr ผ่าน platform มีความยากในการจัดการ
ตัวอย่างปัญหาที่พบ
Application ไม่ได้ใช้ tool ช่วยในการจัดการ log (log4j, logback, slf4j, log4net) และไม่ได้ใช้ stdout
Application มี code เพื่อทำการรวม log และเขียน log โดยไม่อาศัย tool จากภายนอก
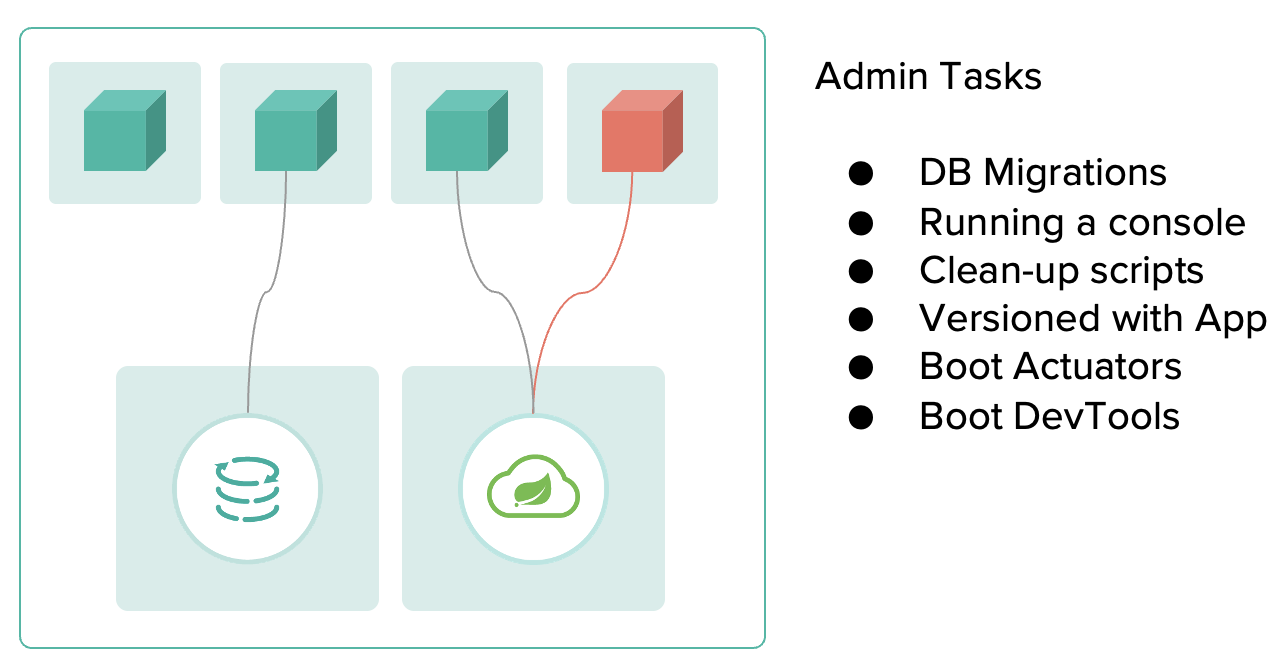
12. Admin Processes
สร้าง process ให้ทำงานแยกส่วนเฉพาะงาน เพื่อจัดการ process ของ application ที่ทำงานบน environment ตัวอย่างเช่น มี shell script เพื่อควบคุม proces หรือ database migration เป็นต้น
Factor Assessment Chart
ตัวอย่างตารางสำหรับทำ Application Assessment ว่า application มีความเหมาะสมที่จะ replatform ไปยัง cloud native platform หรือไม่ โดยถ้า Application ตรงตามข้อกำหนดก็จะได้ 1 แต้ม
Factor Compliant? Effort to Comply Codebase Dependencies Configuration Backing Services Build, Release, Run Processes Port Binding Concurrency Disposability Dev/Prod Parity Logs Admin Processes
หลังจากได้ทำ assessment กับทุก application แล้ว ก็สามารถลำดับ application ที่เหมาะสำหรับ replatform จากแต้มเยอะสุด ในกรณีได้แต้มที่เท่ากัน ให้ดูพิจารณาจากความยากในการปรับเปลี่ยน
จากข้อมูลนี้ก็จะทราบว่า application ไหนเหมาะที่จะย้ายไปยัง cloud native platform ทั้งนี้ยังต้องพิจารณา Factor อย่างอื่นรวมด้วยเช่น Application ที่ย้ายไปยัง cloud native platform ช่วย Business ให้บริการลูกค้าหรือผลตอบประกอบการที่มากขึ้น รวมถึงความพร้อมของทีม คนที่เกี่ยวข้องและเวลา เพื่อใช้ในการตัดสินใจ replatform application ให้ทำงานบน Cloud