
แนวทางเบื้องต้นเพื่อใช้ในการ Sizing ขนาดของ Kubernetes Cluster สำหรับ Application ใช้งานใน Kubernetes Environment สามารถใช้แนวทางดังนี้ในการพิจารณา
ต้องพิจารณาปัจจัยหลักๆ ประกอบด้วย 4 ปัจจัยคือ
Pods per node density
คือจำนวนของ Pod ซึ่งเป็น deployable unit (containers) ที่สามารถทำงานได้ต่อหนึ่งเครื่อง (Node) โดยเราต้องมีข้อมูล
- vCPU ที่ pod ใช้งาน อาจจะใช้ cpu limit (ปกติจะต้องทำ cpu limit ไว้ เพื่อไม่ให้ pod ใช้ cpu ของเครื่องหมดจนส่งผลกระทบทั้ง cluster)
- vCPU ของเครื่อง (Node) สำหรับใช้ในการ run pod
- vCPU ทั้งหมดของเครื่อง (Node)
- เปอร์เซ็นต์ของ cpu ที่จะ reserve ไว้สำหรับงานอื่นๆ เช่น system process
จากนั้นก็จะสามารถหาค่า pod per node density ได้จากการหาว่ามี vCPU สำหรับใช้ได้จริงเท่าไหร่ แล้ว หารด้วยค่าเฉลี่ยของ vCPU ที่ pod ใช้งาน เช่น
Node VM มี 8 vCPU และต้องการ reserve vCPU ไว้ 15% สำหรับ system process โดยค่าเฉลี่ยที่ pod ใช้งาน cpu core คือ 0.2 vCPU ต่อ Pod ก็จะหา pod per node density ได้ดังนี้
vCPU ที่ใช้งานได้ = 8 – (8*15/100) = 6.8 vCPU
Pod per node density = 6.8/0.2 = 34
** การกำหนดค่าเฉลี่ย vCPU ที่ pod ใช้งาน ต้องพิจารณา pods per CPU core จากคำแนะนำของ Kubernetes ที่ 1 CPU core จะสามารถรองรับได้ที่มากที่สุด 10 pods และจำนวน pod ต่อ Node ไม่ควรเกิน 110 pods – https://kubernetes.io/docs/setup/best-practices/cluster-large/
Master Node’s hardware config
ใช้ข้อมูลจาก kubernetes.io สำหรับเลือกขนาดของ Master Node
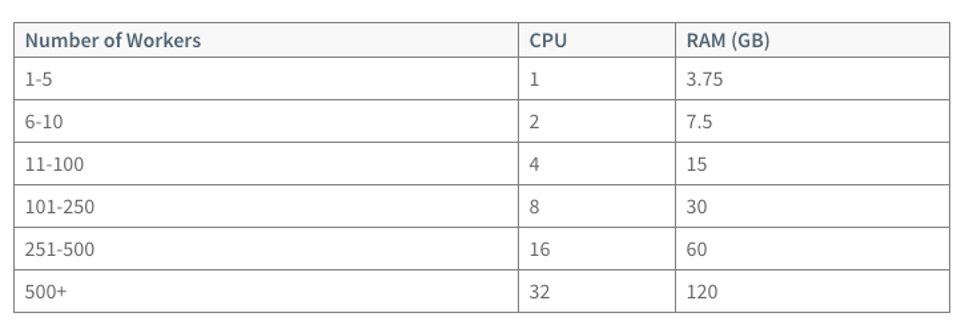
และต้องพิจารณา size ของเครื่องเพื่อรองรับ etcd คือ

ซึ่งถ้าต้องการ high availability จะต้องมีจำนวน node เป็นเลขคี่ตั้งแต่ 3 ขึ้นไป (Quorum)
ตัวอย่างเช่น ถ้าเรามี Worker node อยู่ 11 Node และต้อง support client จำนวน 500 client เราต้องใช้ Master node ด้วย spec 4vCPU memory 15 GBs
Number of Master Node in Cluster
เพื่อให้ระบบทำงานได้แม้จะมี Master node บางตัวไม่สามารถทำงานได้ ต้องพิจารณาจำนวนของ Master node ดังนี้
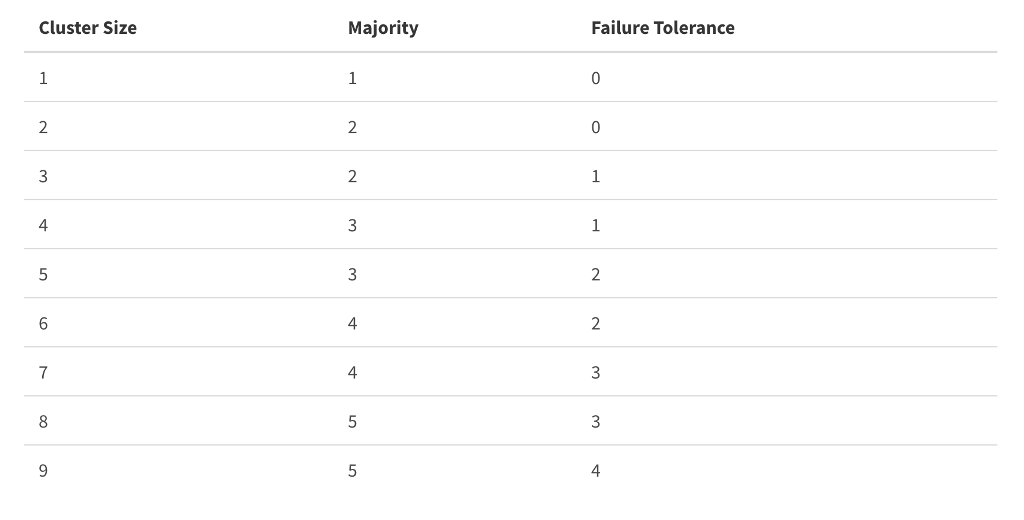
ตัวอย่างเช่น ถ้าต้องการให้ระบบยังคงทำงานได้ กรณีที่มี Master Node 2 ตัวเกิดปัญหา เราต้องเลือกจำนวน Master Node เป็น 5
High Availability and Fault Tolerance
ปัจจัยที่ต้องใช้ในการพิจารณามีดังนี้
- จำนวน Node ที่มีปัญหา ณ เวลาใดเวลาหนึ่งพร้อมกัน
- Node ที่ต้อง reserve ไว้ในกรณีที่มีการ update ระบบ
- Pod per node density
- จำนวน Node ที่เหลืออยู่หลังจาก Failure
- จำนวน Capacity ที่เหลือสำหรับให้ Pod ทำงานได้หลังจาก Failure
- จำนวน CPU core ที่เหลืออยู่หลังจาก Pod ทำงานเรียบร้อย หลังจาก Failure (rescheduling)
การหาจำนวน Node เช่น ถ้าเรามี 100 pods และต้องการให้ run 34 pods ต่อ node โดยสามารถ fail ได้ 2 Node ต่อเนื่อง และรองรับกรณี upgrade ระบบ ก็จะคำนวณ sizing ของ Node ได้คือ
100/34 + 2 + 1 = 6 worker node
การหา capacity ที่เหลือ และ pod per node density หลังจาก failure
เช่น มี pod จำนวน 100 pods ทำงานกระจายใน 6 node เมื่อมี 2 nodes ไม่สามารถให้บริการได้
จำนวน pod per node density เบื้องต้น = 100/6 = 16.6
จำนวน node ที่เหลืออยู่หลังจาก failure = 4 Node ซึ่งก็คือ resource หายไป 33% ของทั้งหมด
ทำให้ pod per node density เพิ่มขึ้นเป็น = 100/4 = 25
หลังจากได้ pods per node density แล้วต้องคำนวณด้วย cpu core ที่ pod ใช้งานถึงจะ sizing ขนาดของ node ได้ว่าจะต้องเผื่อ cpu และ memory ไว้ที่เท่าไหร่ถึงจะเหมาะสม
** Kubernetes support cluster auto scaling ได้ในกรณีที่ pod ไม่สามารถ scheduling ได้เนื่องจาก resource มีไม่เพียงพอ https://kubernetes.io/docs/concepts/cluster-administration/cluster-autoscaling/ แต่ก็จะมีช่วงเวลาที่ pod ไม่สามารถทำงานได้ในระหว่างที่มีการสร้าง node ใหม่เพื่อ join เข้ามาใน cluster
Workload Characteristic
เพื่อที่จะได้ค่า cpu และ memory ที่ pod ต้องการใช้จะต้องมีข้อมูลการทำงานจริงของ pod แล้วนำมาหาค่าเฉลี่ยเพราะแต่ละ pod ประกอบด้วย container ที่ application ถูกสร้างด้วย technology, architecture, algorithm ที่มี load หรือ usage แตกต่างกันในแต่ละช่วงเวลาการใช้งาน ตัวอย่าง memory ต่อ container ของแต่ละภาษา เช่น
- Legacy JEE. 2Gb+ mem per container
- SpringBoot 1Gb+ mem per container
- NodeJS. 256Mb+ mem per container
- Go 256Mb+ mem per container
Case Study
หา Sizing ของ Kubernetes Cluster เพื่อรองรับ 100 Springboot containers โดยมีข้อมูลดังนี้
- Pod ทำงานโดยใช้ 0.2 vCPU และ Memory 0.4 GB
- จำนวน pod per node density เท่ากับ 34
- สามารถ fail ติดต่อกันได้ 2 ครั้ง
- มี node ไว้ reserve สำหรับการ upgrade
- ต้องมีการสำรอง resource ไว้ 15% สำหรับระบบ

