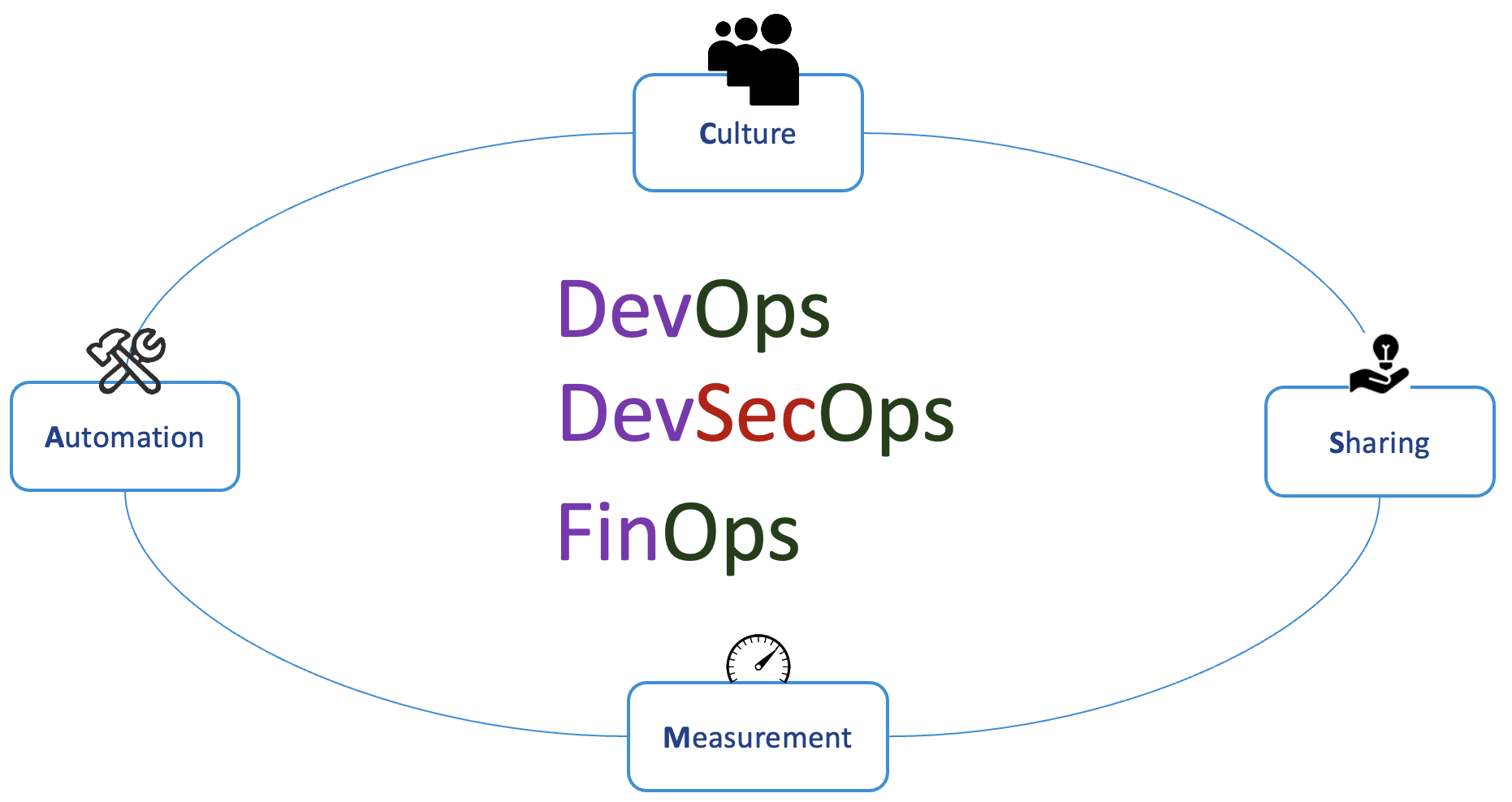
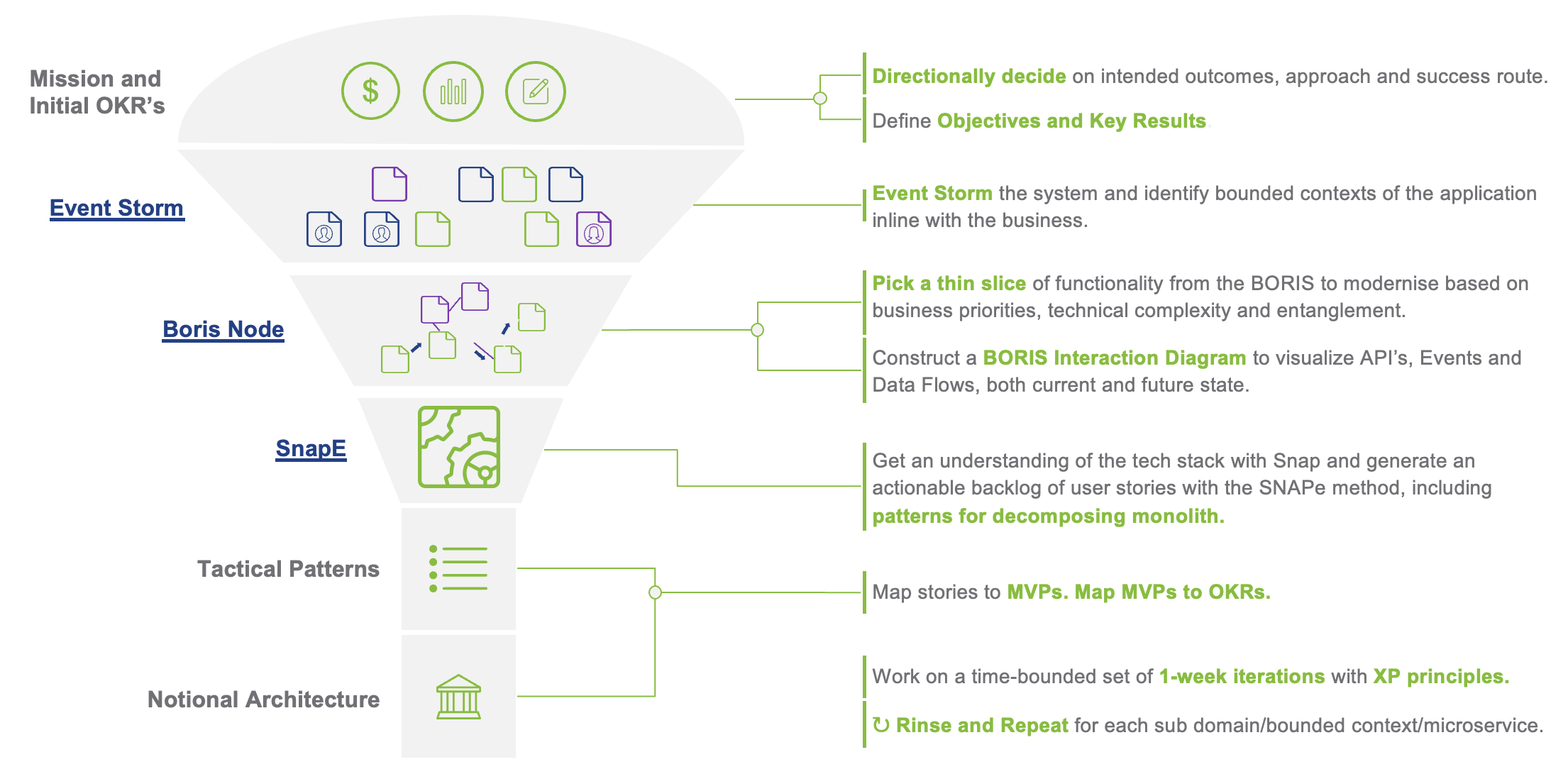
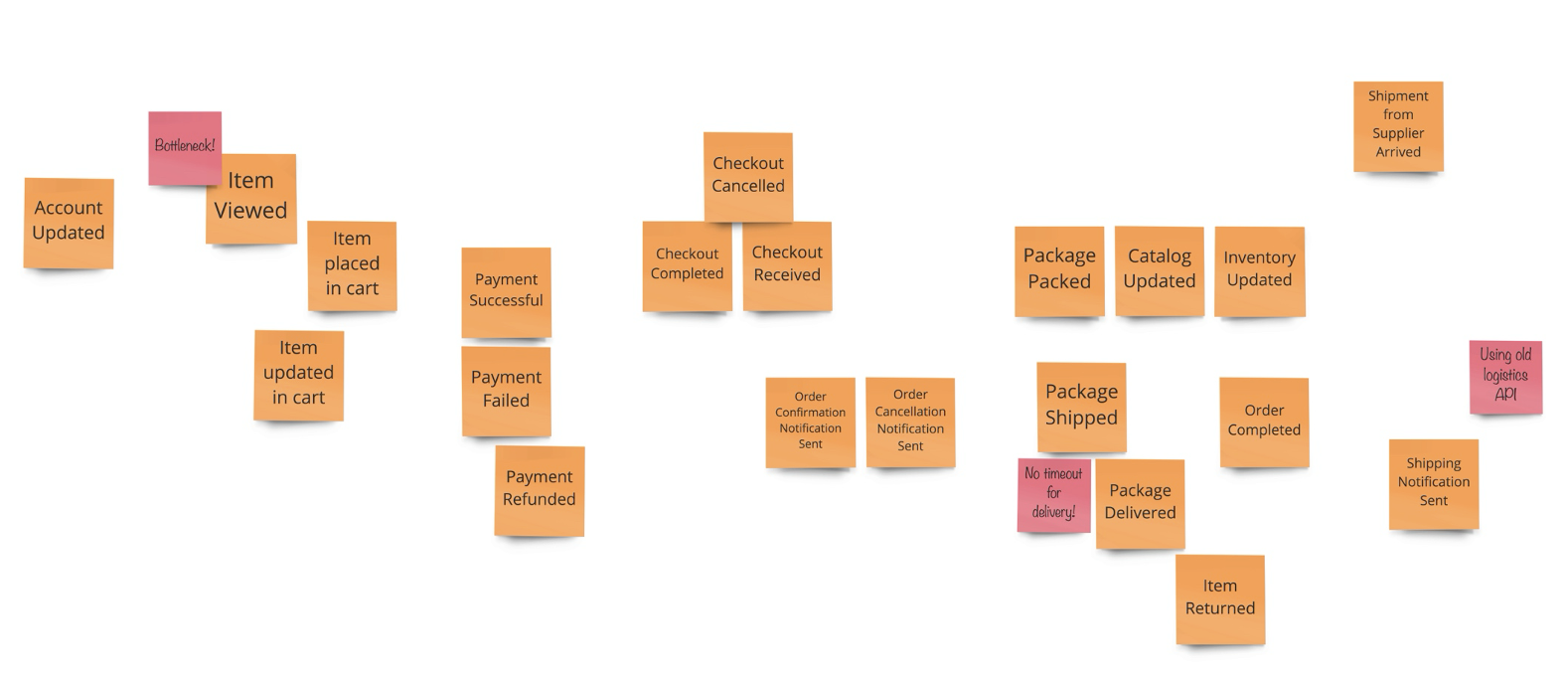
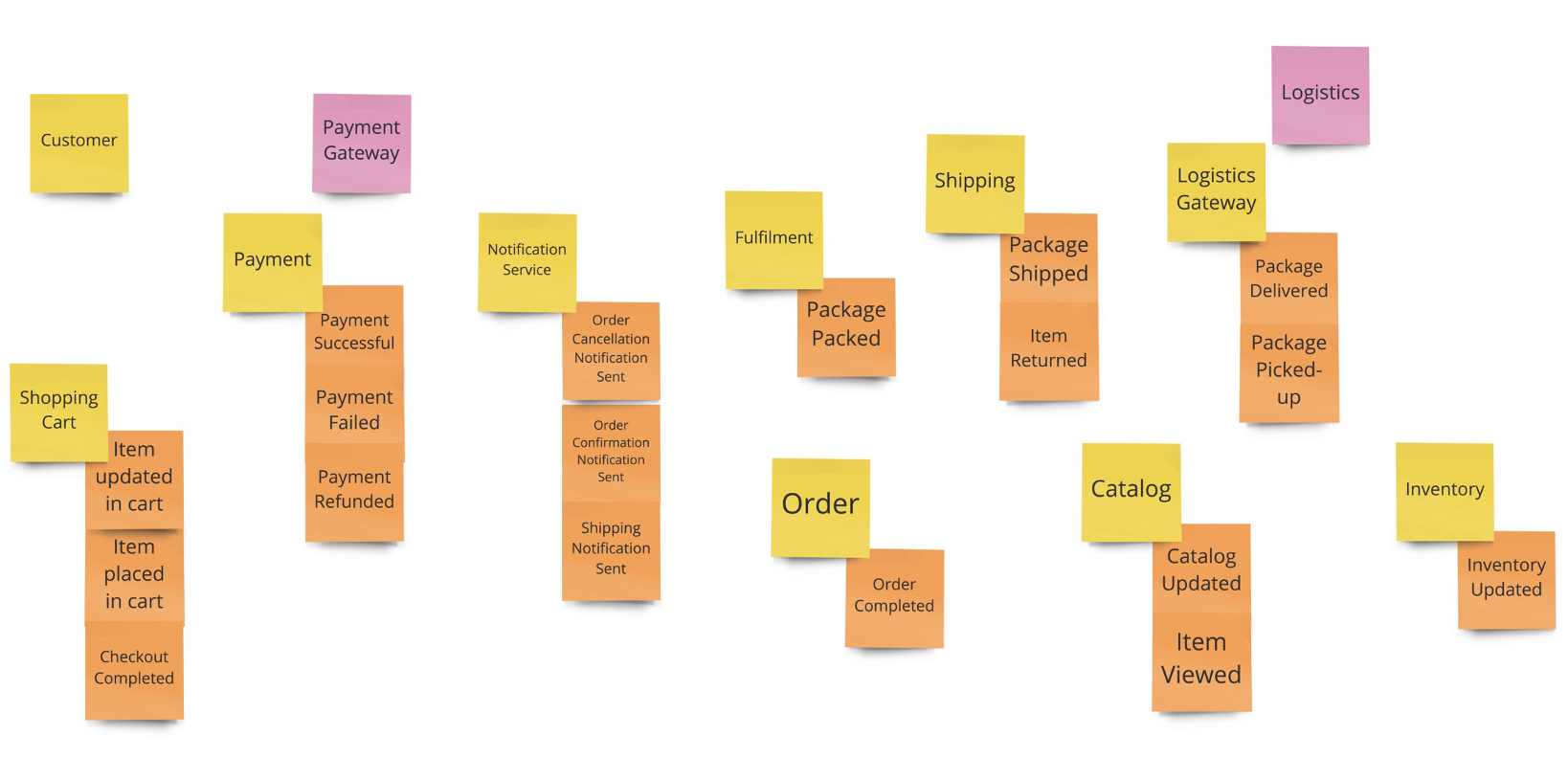
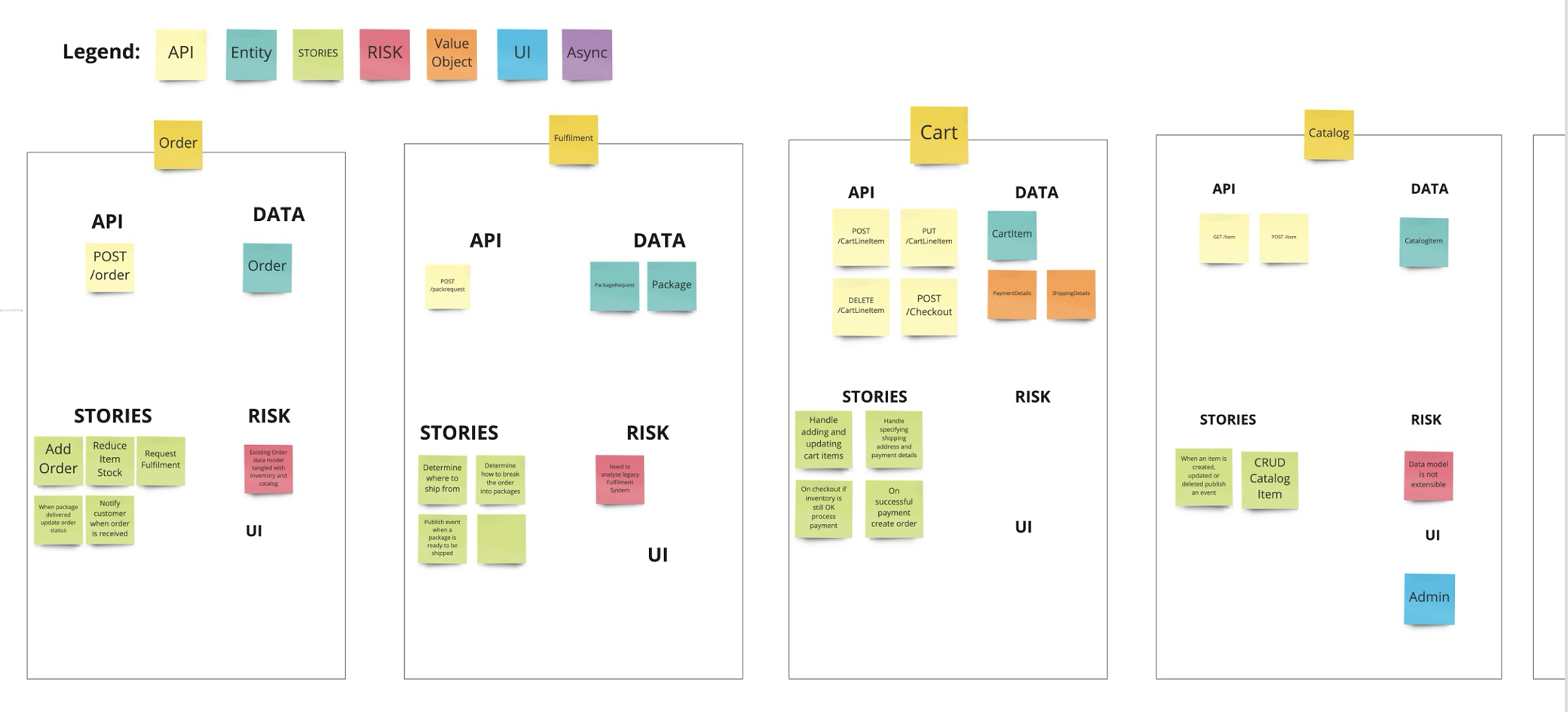
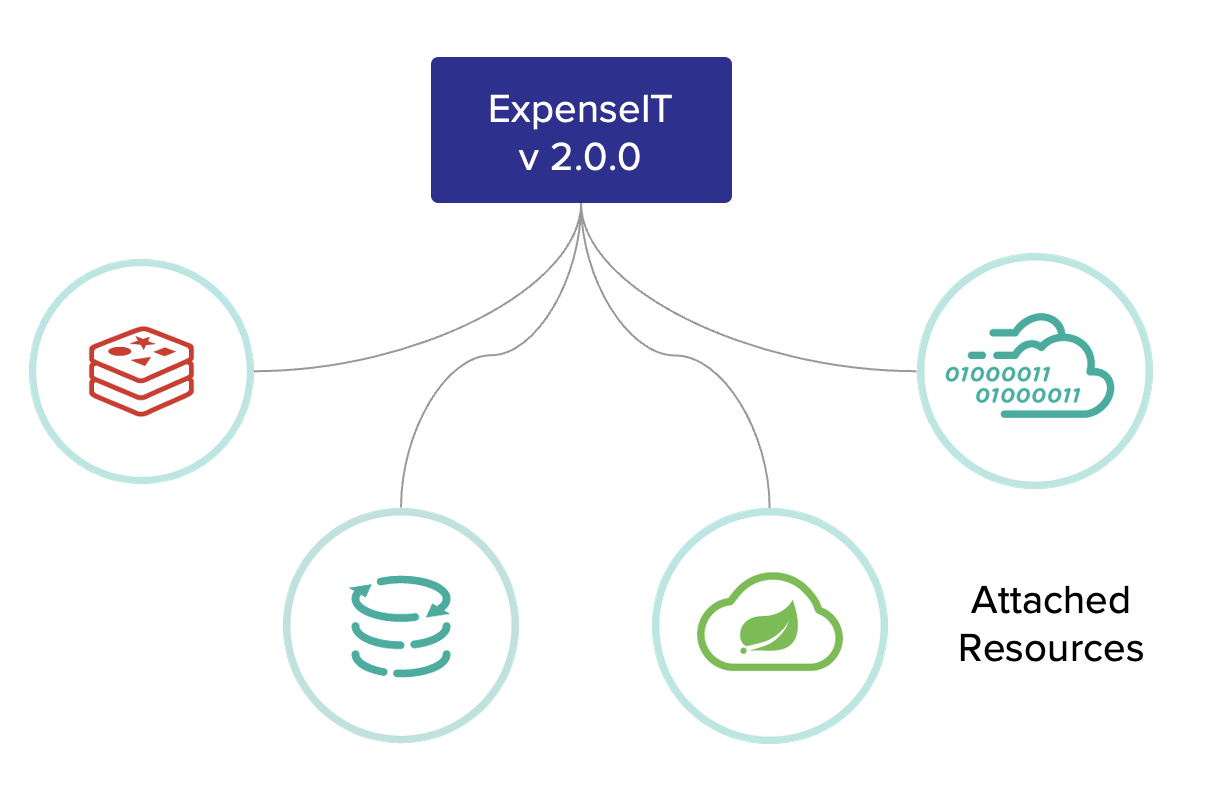
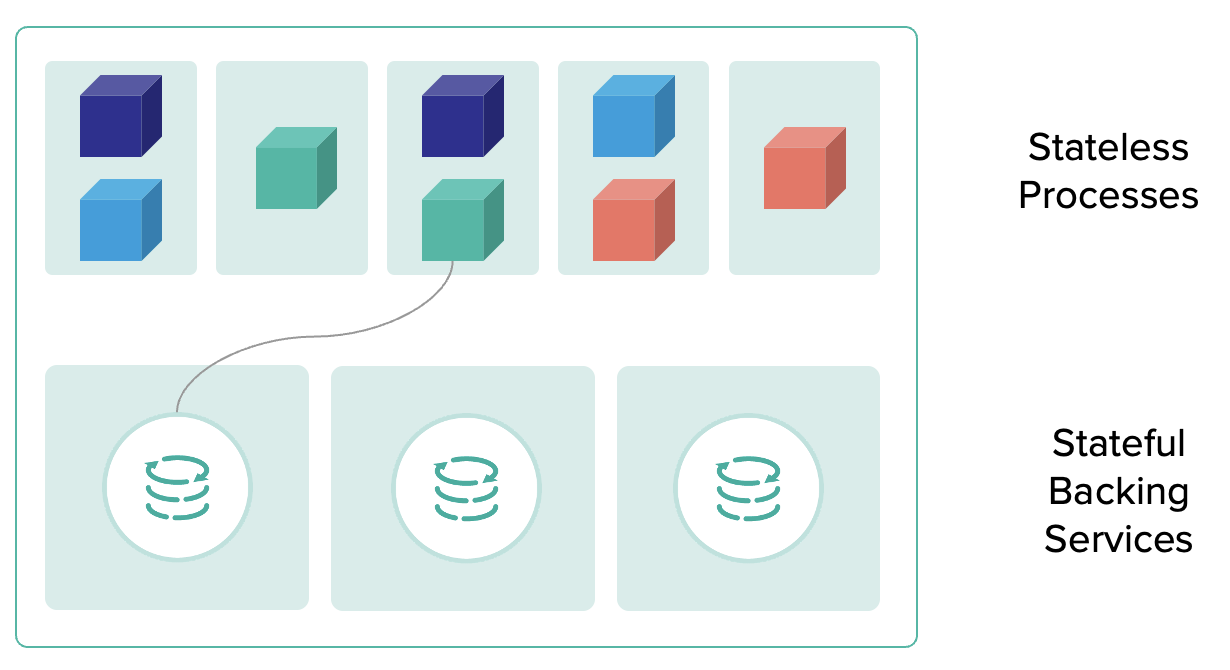
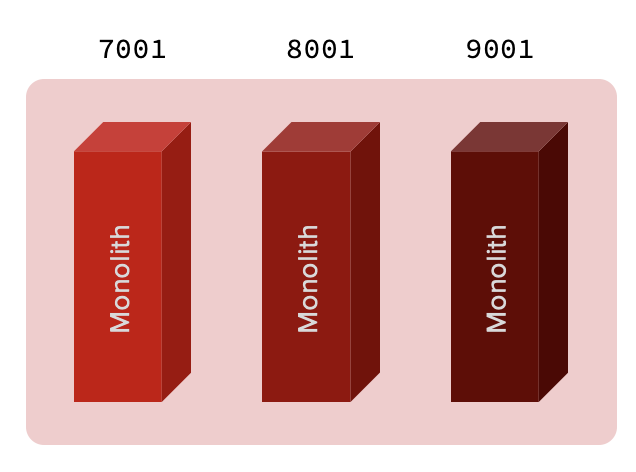
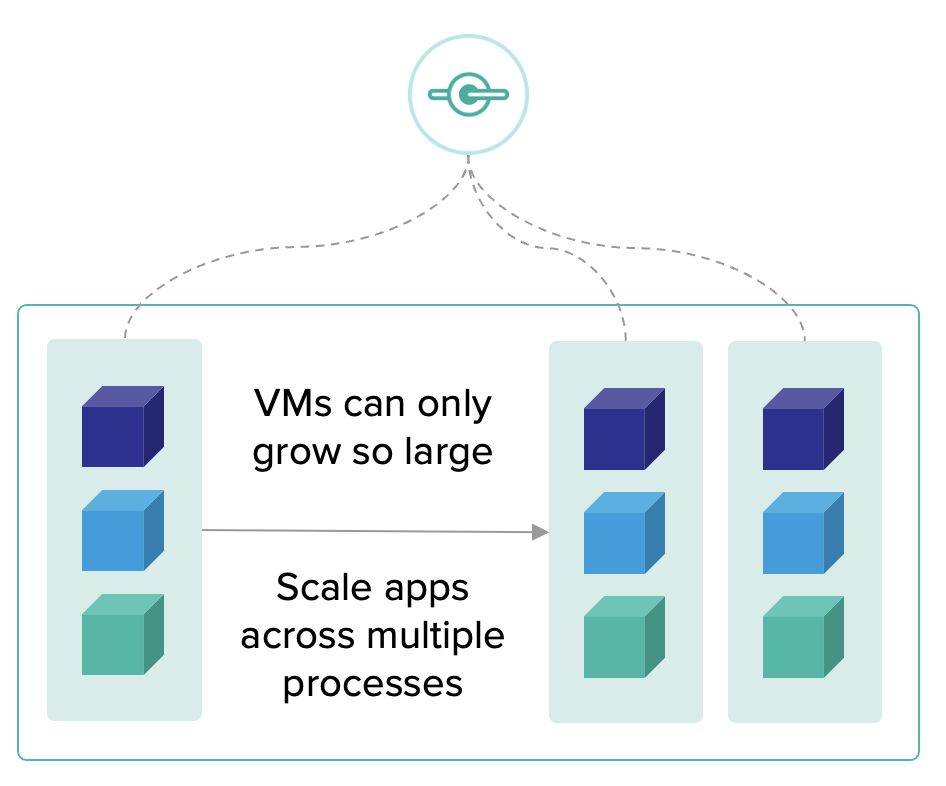
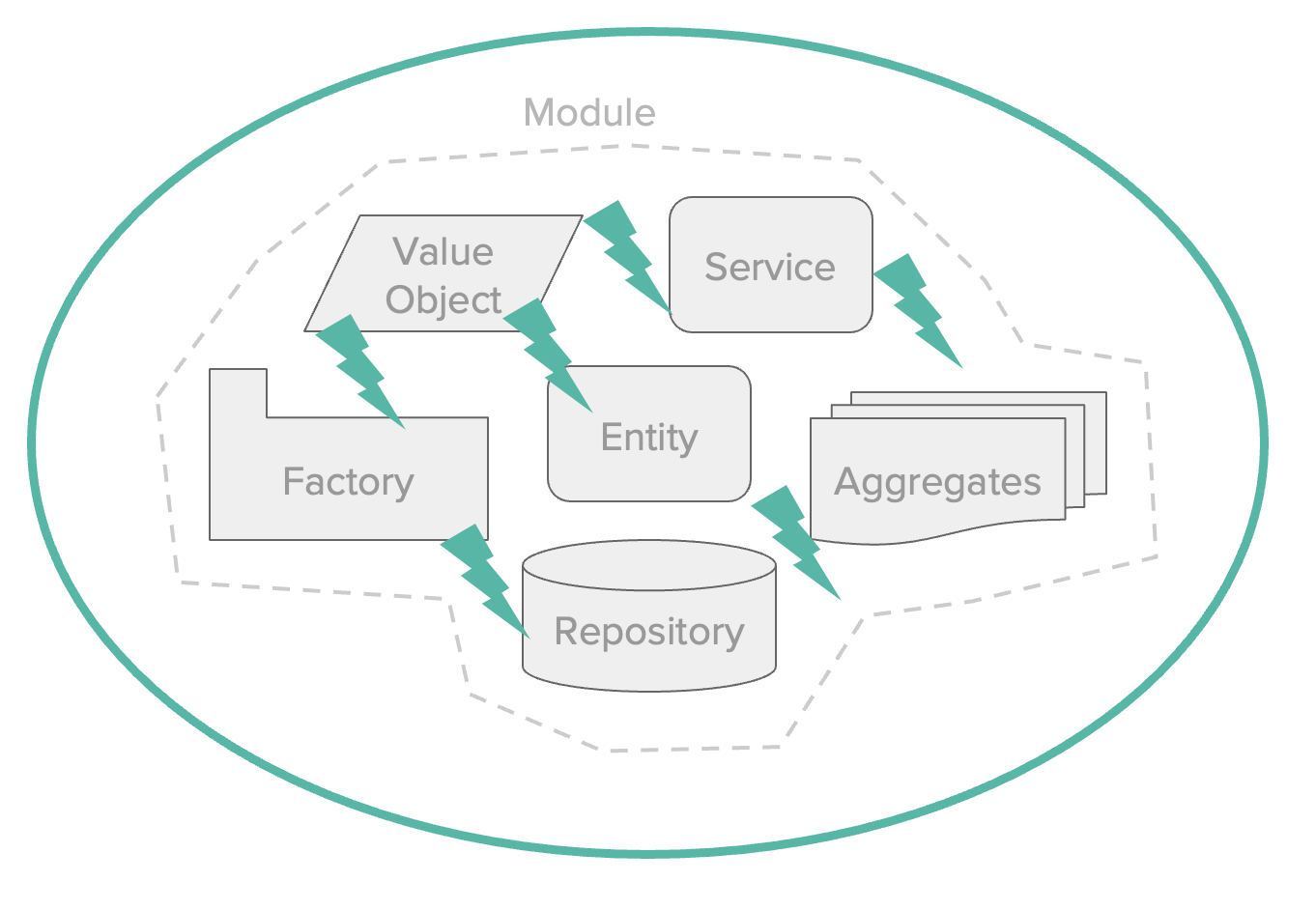
รูปแบบการจัดการทีมงาน เมื่อต้องรองรับการทำงานแบบ agile บางครั้งจะมองว่าเป็นเรื่องของทีม development ที่จริงแล้วต้องมองภาพรวมของทั้ง IT จึงจะสามารถขับเคลื่อนได้อย่างมีประสิทธิภาพ
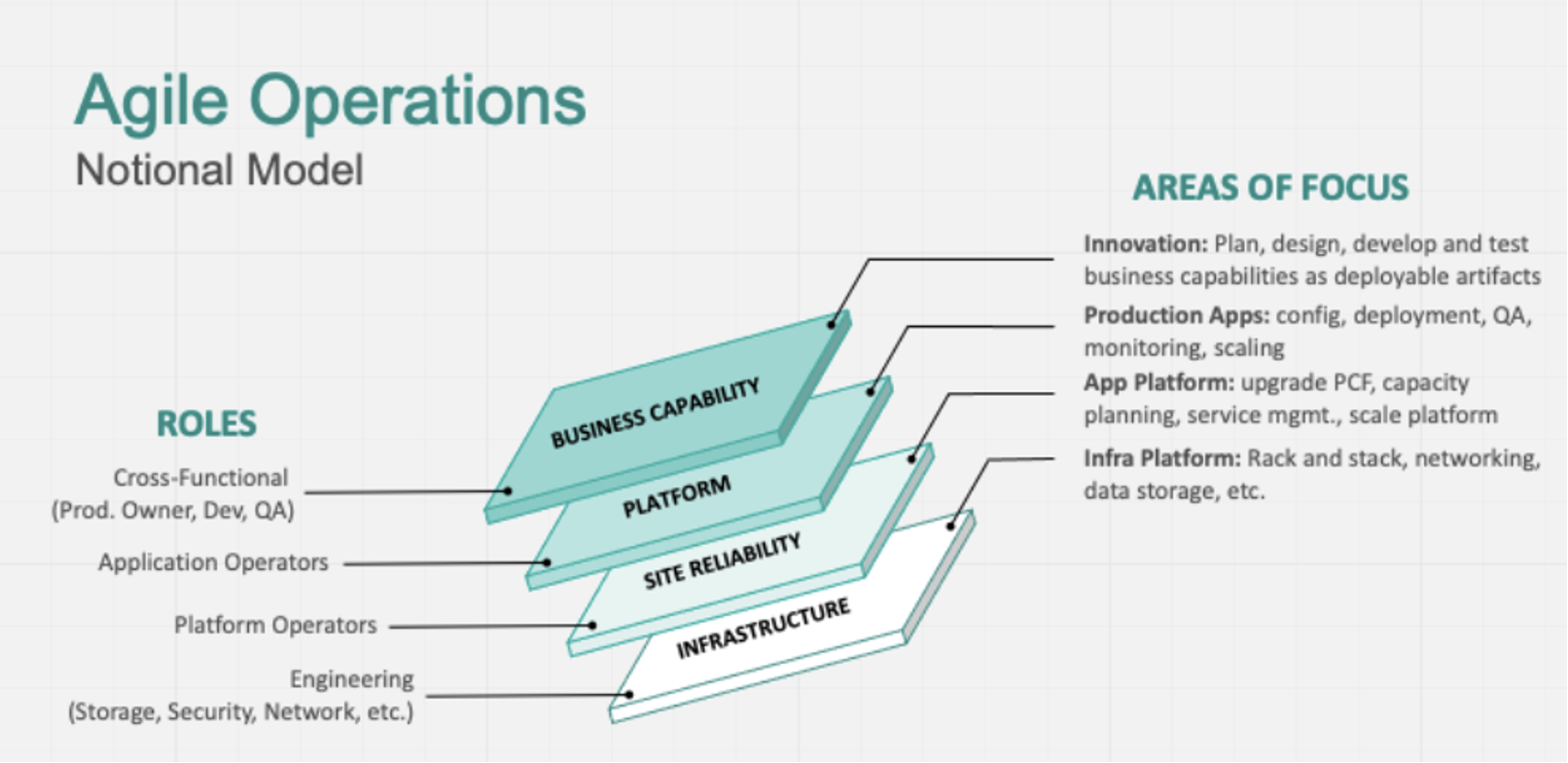
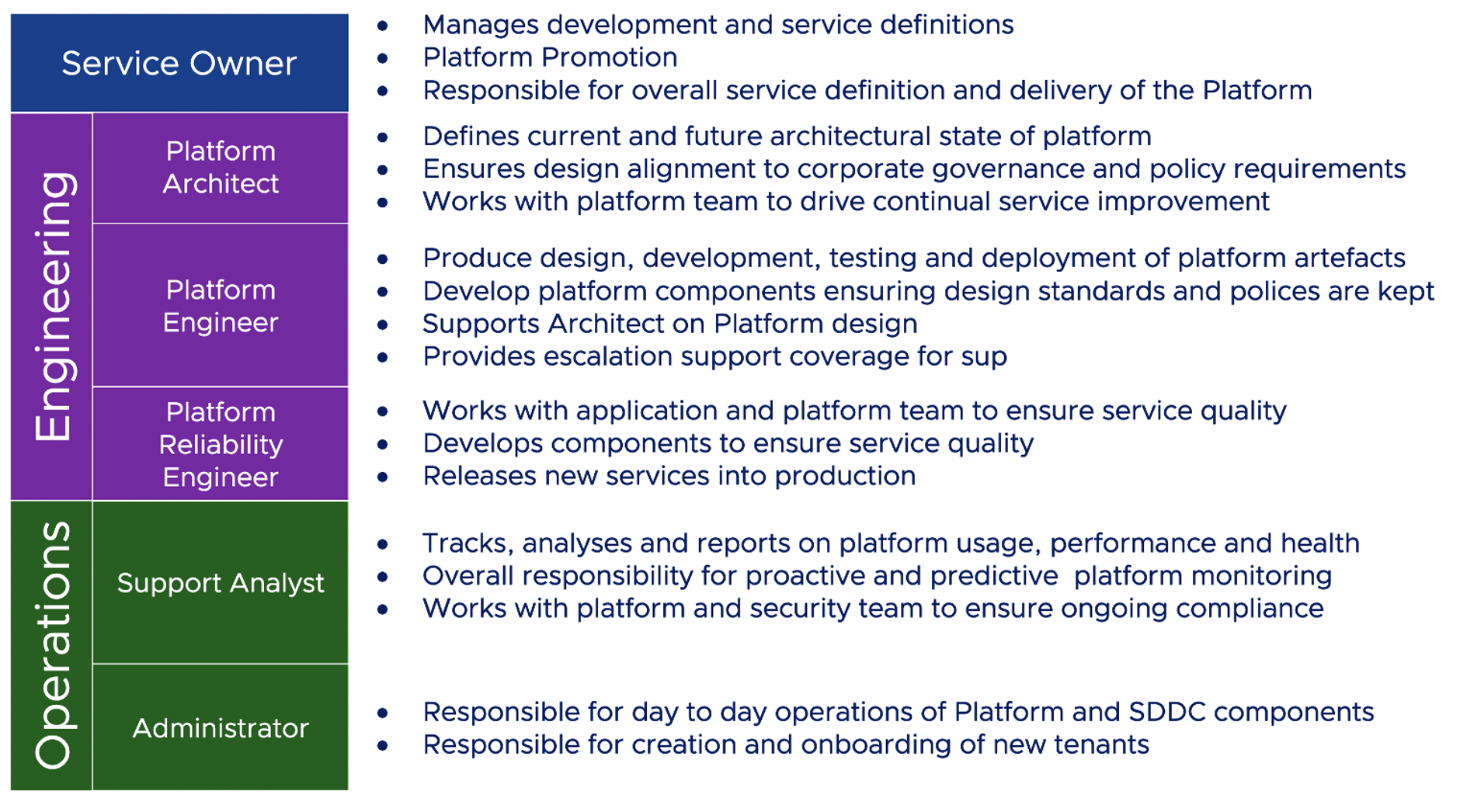
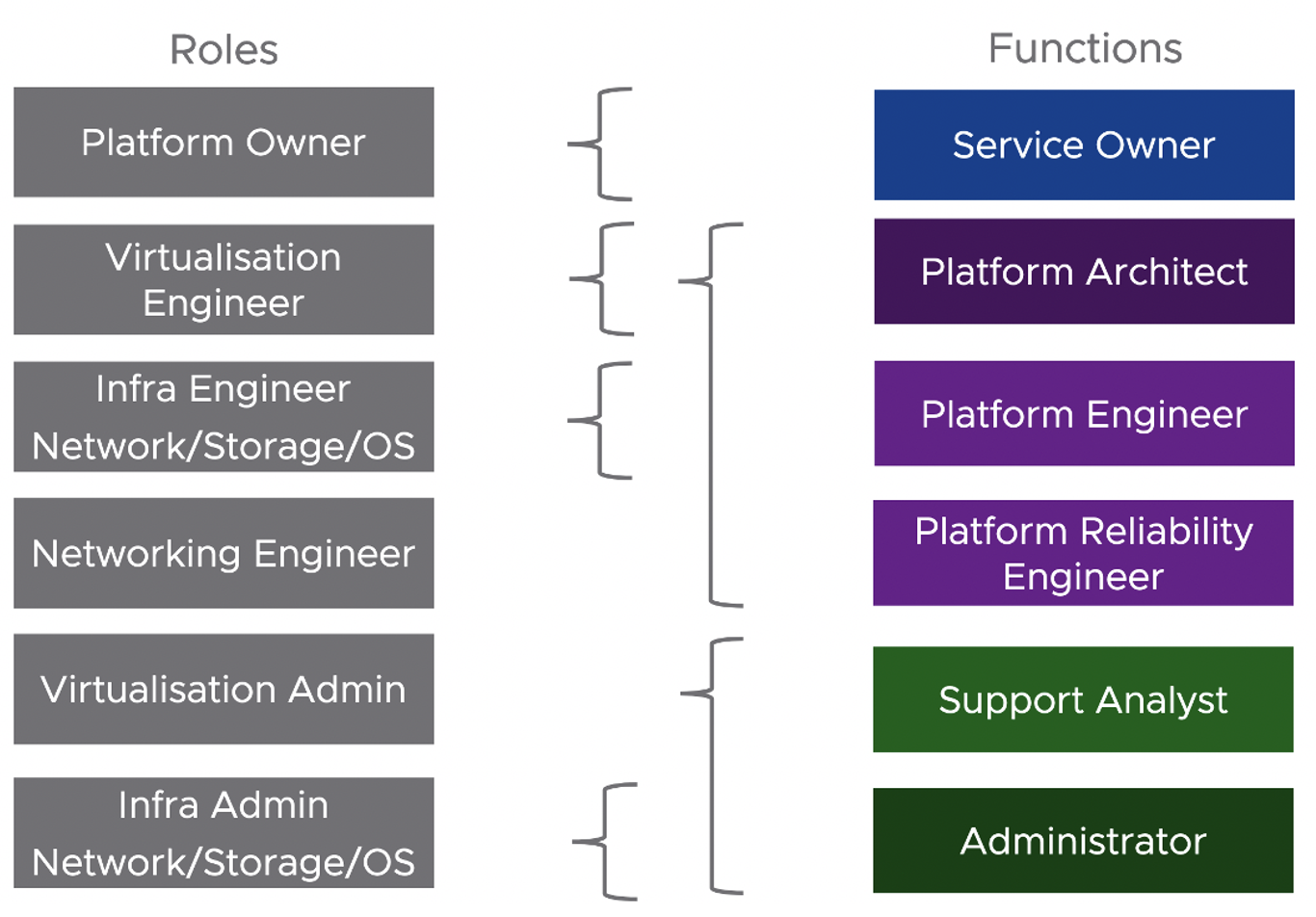
ด้วยการแบ่ง Roles และสิ่งที่ต้อง focus ในแต่ละ layers ของ IT landscape คือ
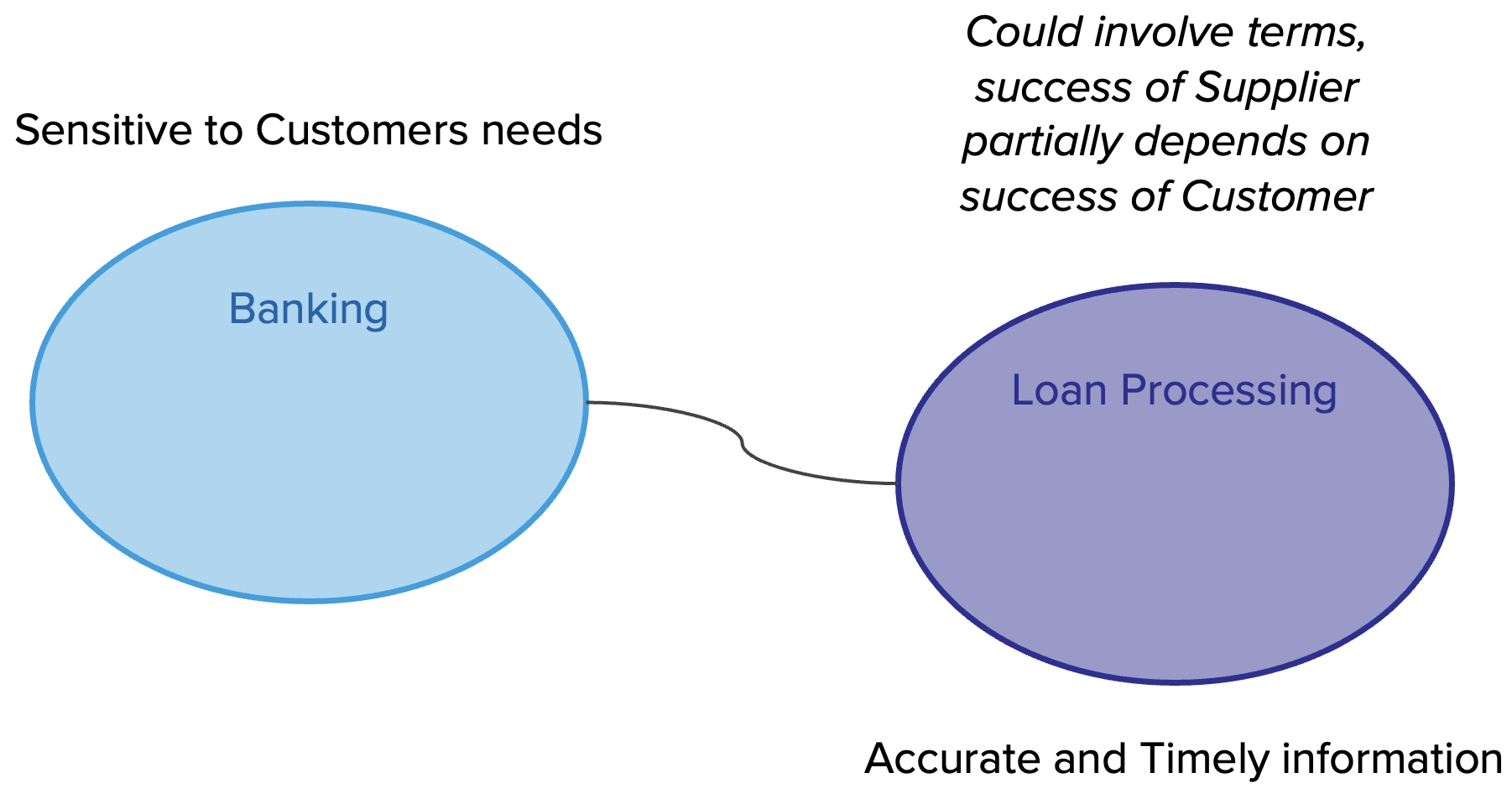
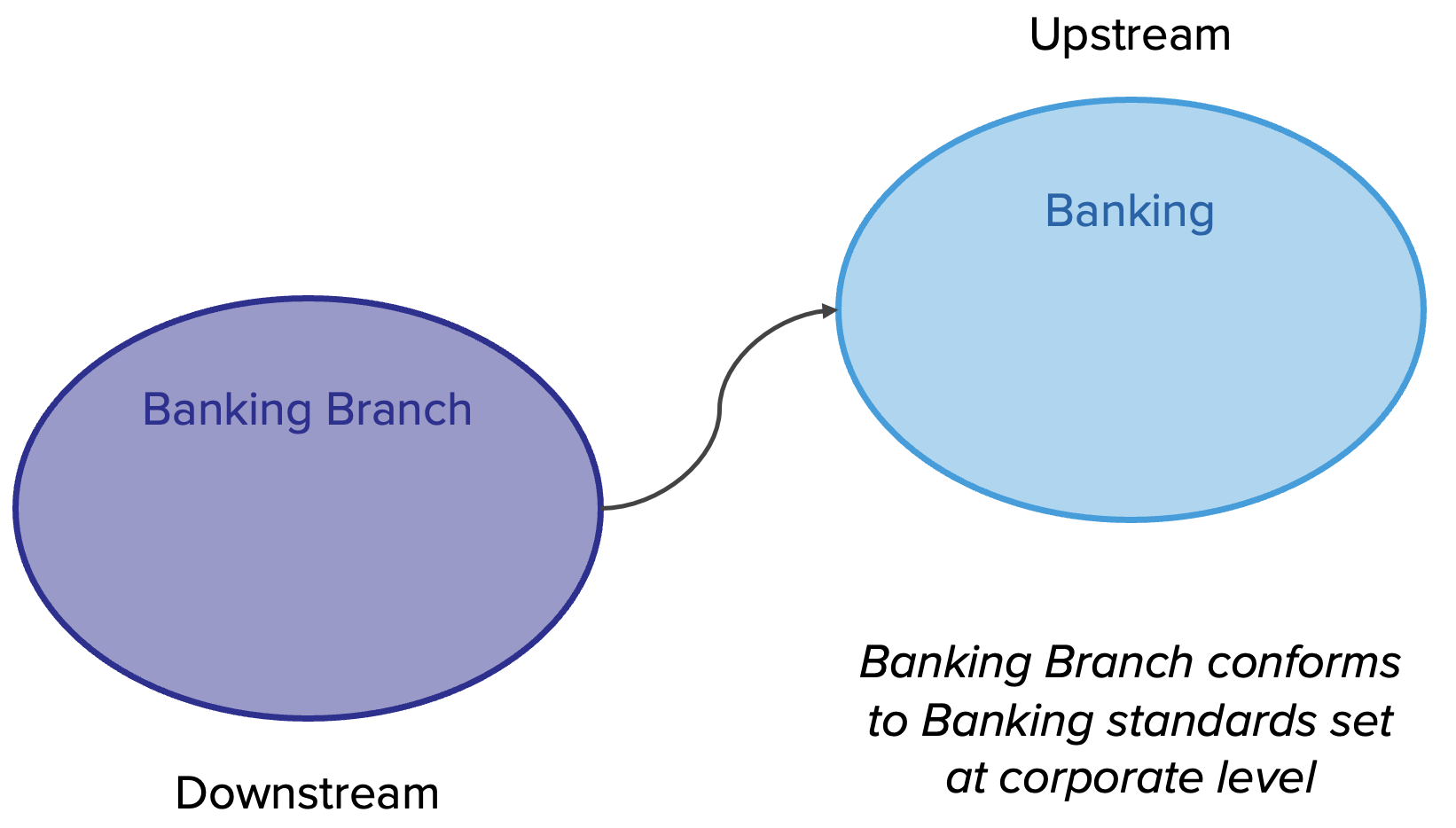
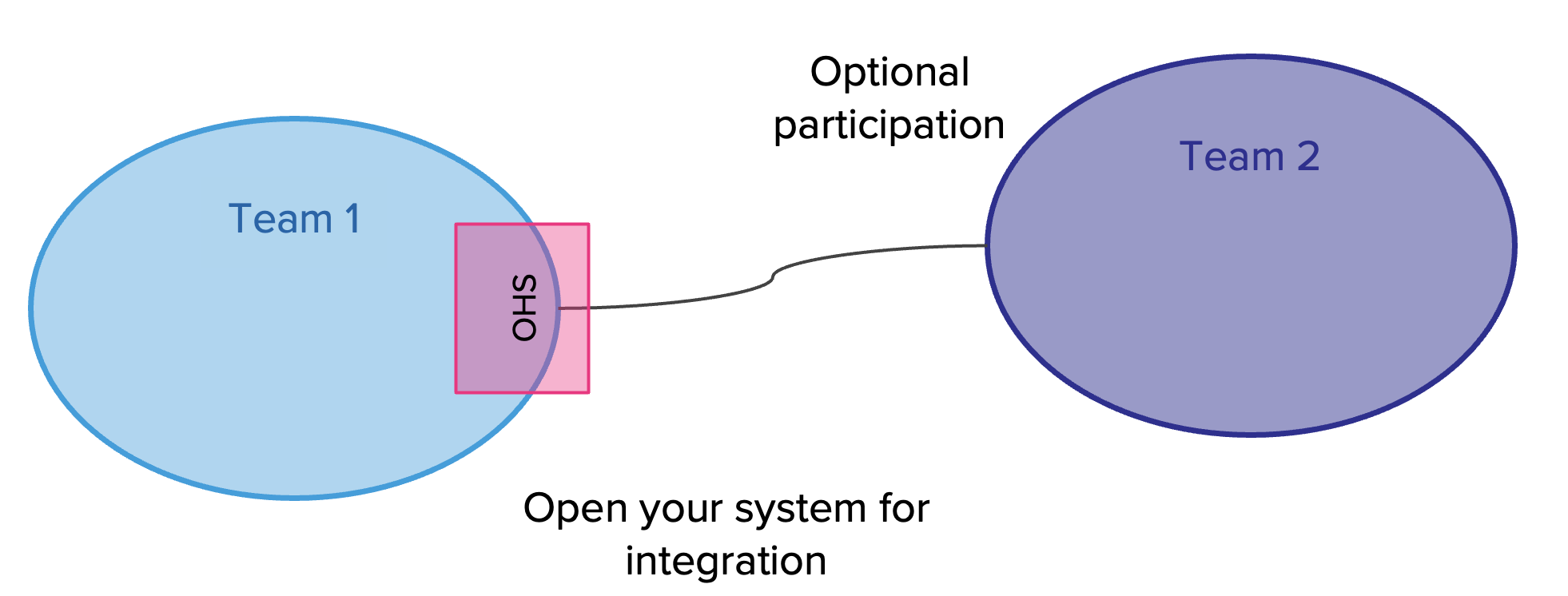
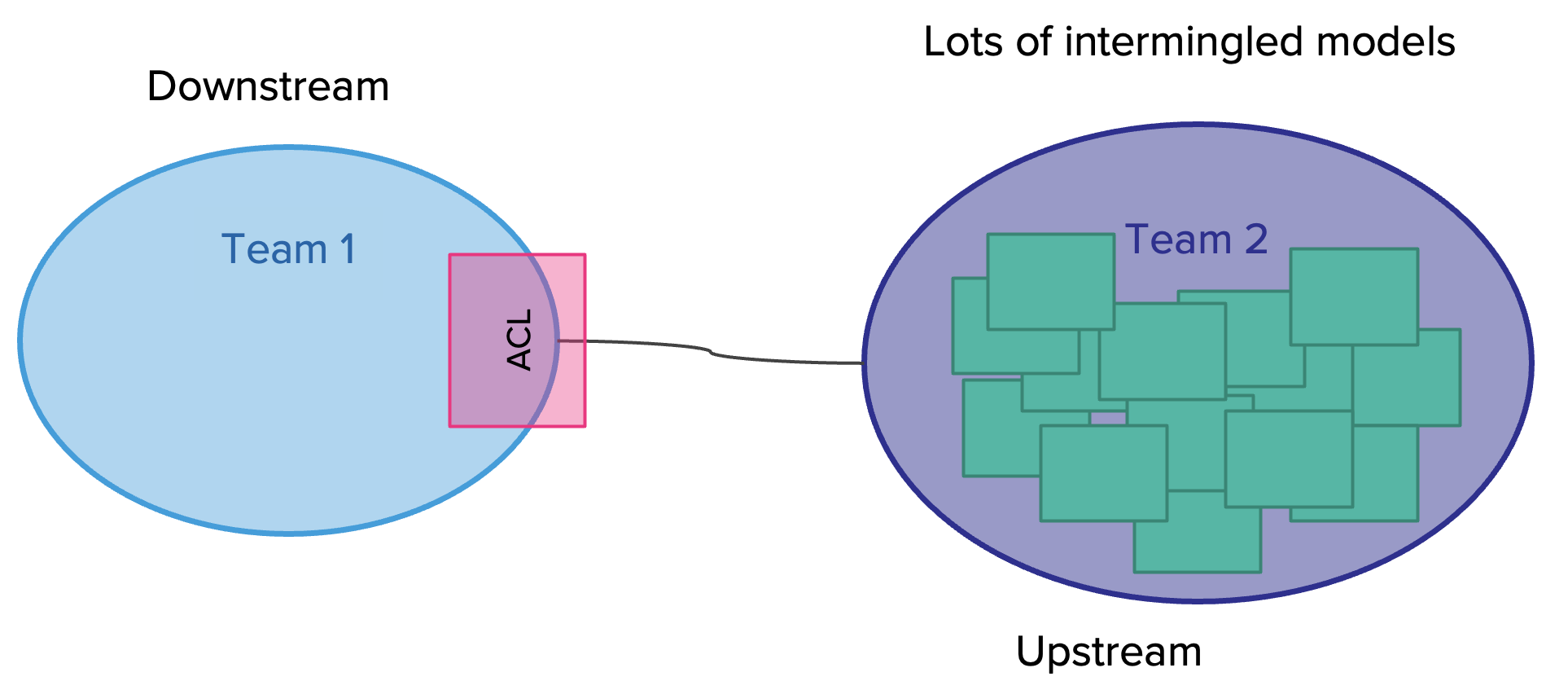
Business Capability ต้องมี product team ที่จัดการในลักษณะ cross-functional โดยประกอบด้วย product owner, designer, dev, QA รับผิดชอบในการ develop application ตลอด life cycle เช่น plan, design, develop และ test
แต่ถ้าเราจะมองในมุม functional ของงานและแบ่งแยกย่อยลงไปอีกก็สามารถใช้รูปแบบนี้เป็น model ก็ได้เช่นกัน
และเมื่อ map role กับ functions งานก็จะได้ดังรูป
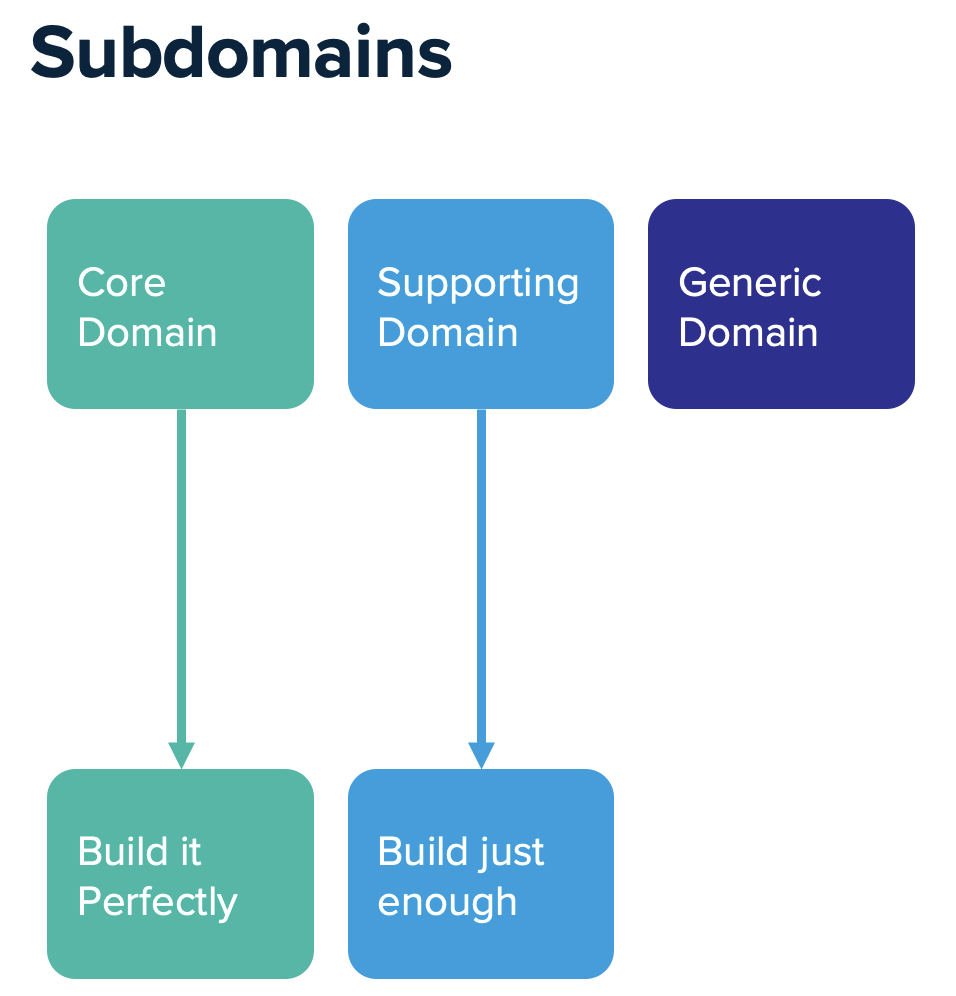
การจะเลือกรูปแบบใดนั้นขึ้นอยู่กับความซับซ้อน และขนาดของระบบที่แต่ละองค์กรมีความแตกต่างกัน ดังนั้น role ของ IT ในแต่ละองค์กรจึงไม่จำเป็นต้องเหมือนกันทุกองค์กร
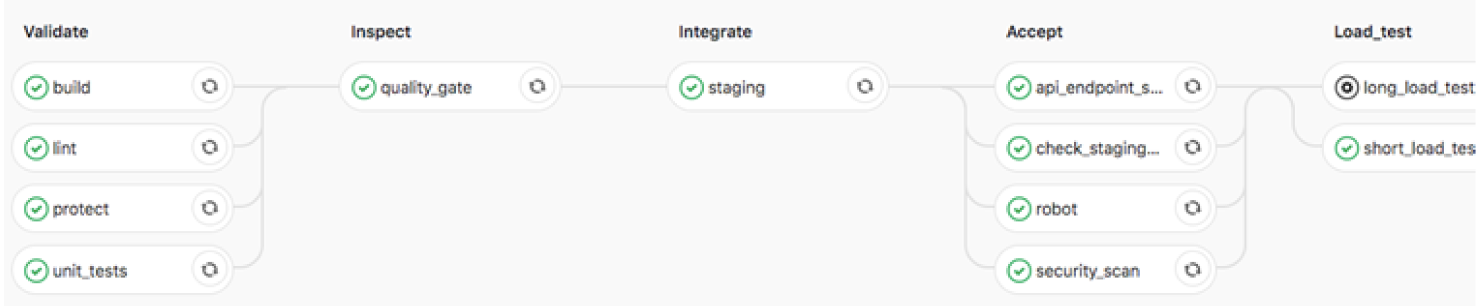
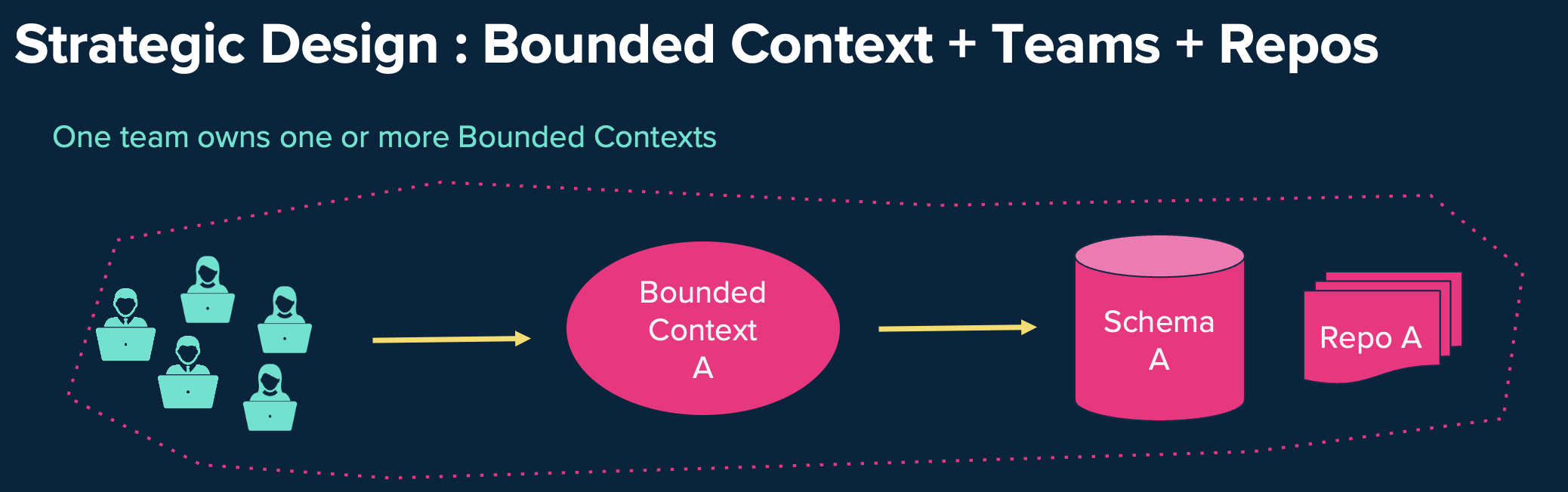
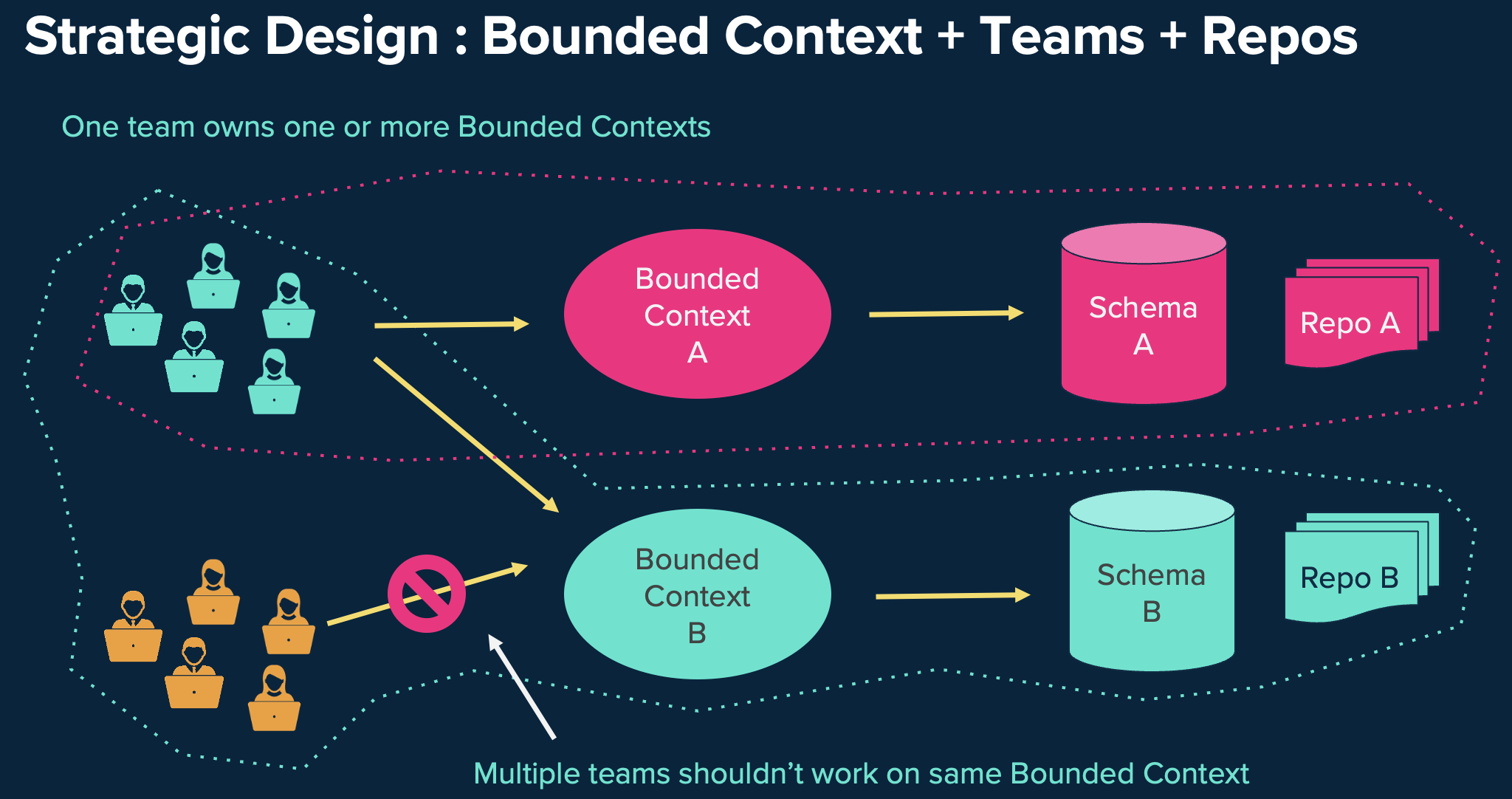
Source code จะต้องถูกจัดการผ่าน Gitlab หรือ git version control รวมถึง Infra code หรือ technical code อื่นๆ เป็นการจัดการ code ที่เดียวเพื่อความชื่อถือและถูกต้องเสมอสำหรับ development team (one source of truth) โดยมีหลักพิจารณาคือ
Trunk Based Development เป็นการให้ engineer ทำงานอยู่บน development branch (main branch) ในระยะเวลาที่สั้น (short iterations) ดีกว่าให้มีหลายๆ release หรือ feature branch เพื่อลดปัญหาเรื่องความซับซ้อนและยากลำบากในการ merge code (merge conflicts)
ทำการ automate test ในทุกระดับทั้งที่เป็น functional และ non-functional โดยเลือกใช้ tool ที่เหมาะสมในแต่ละ test case การใช้ automate test tool จะทำให้เห็นปัญหาก่อน User ประกอบด้วย
Unit เป็นการทดสอบส่วนไดๆ ใน code โดยต้องมี coverage ในการ test ที่เหมาะสม
Integration เป็นการทำ end to end test ประกอบด้วยการทำ API test และ UI test เพื่อ simulate การใช้งานของ User
Performance เป็นการ load test เพื่อให้มั่นใจว่า application สามารถทำงานได้ในภาวะการณ์ต่างๆ ได้ ทั้งกรณีที่มี request และมีการส่ง data (payload) เข้ามามากกว่าปกติ
Security Testing
Web app และ Mobile application จำเป็นต้องมีการตรวจสอบความปลอดภัยมากกว่าเดิม จากการเข้าถึงของผู้ใช้งานได้ทั่วไป ดังนั้นโดยทั่วไปจึงมีการทำ hardening และ end-to-end penetration test จากหน่วยงานภายนอกก่อนที่จะขึ้น production การทำ security testing สามารถทำได้หลายวิธี โดยการทำให้เป็นส่วนหนึ่งของ agile process และ devops
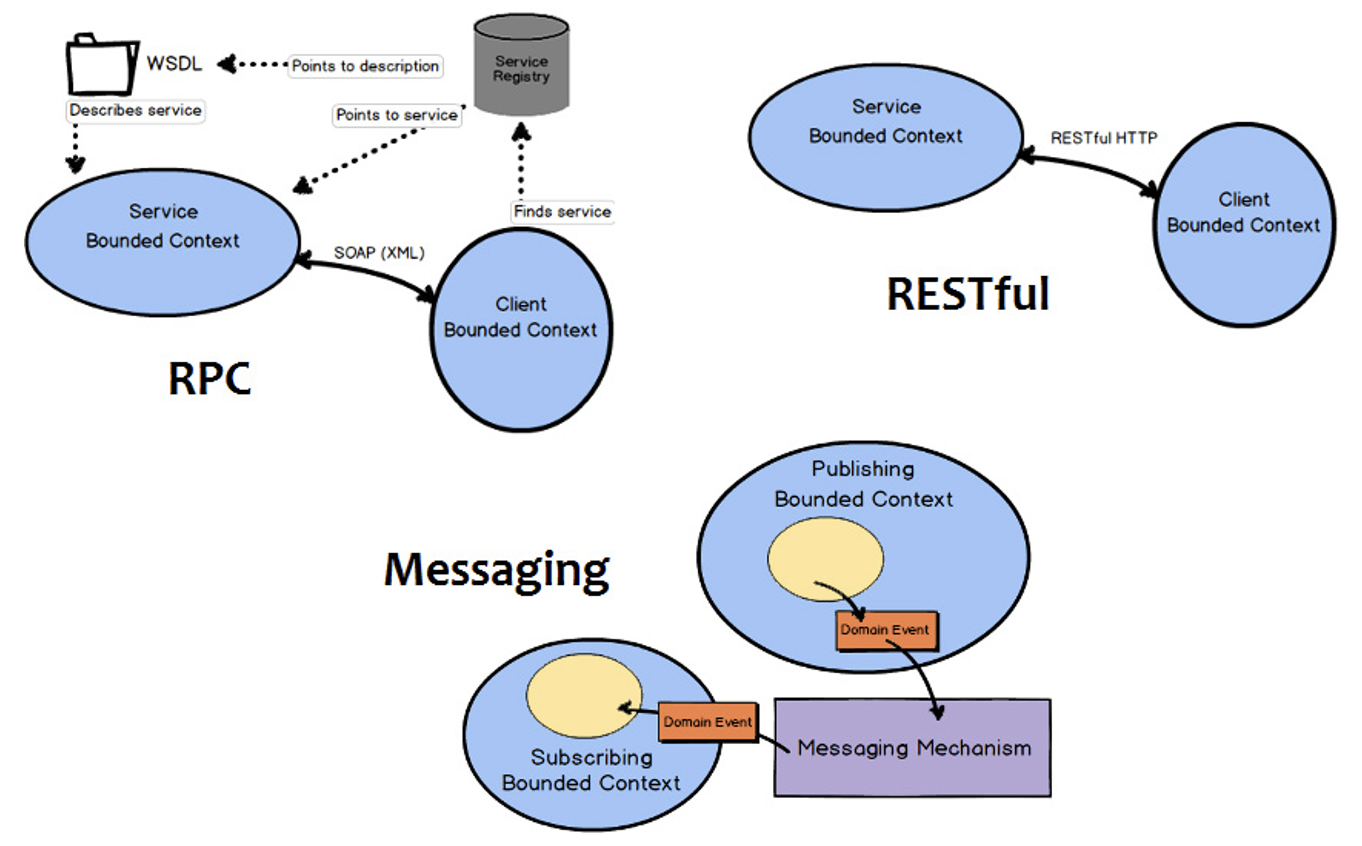
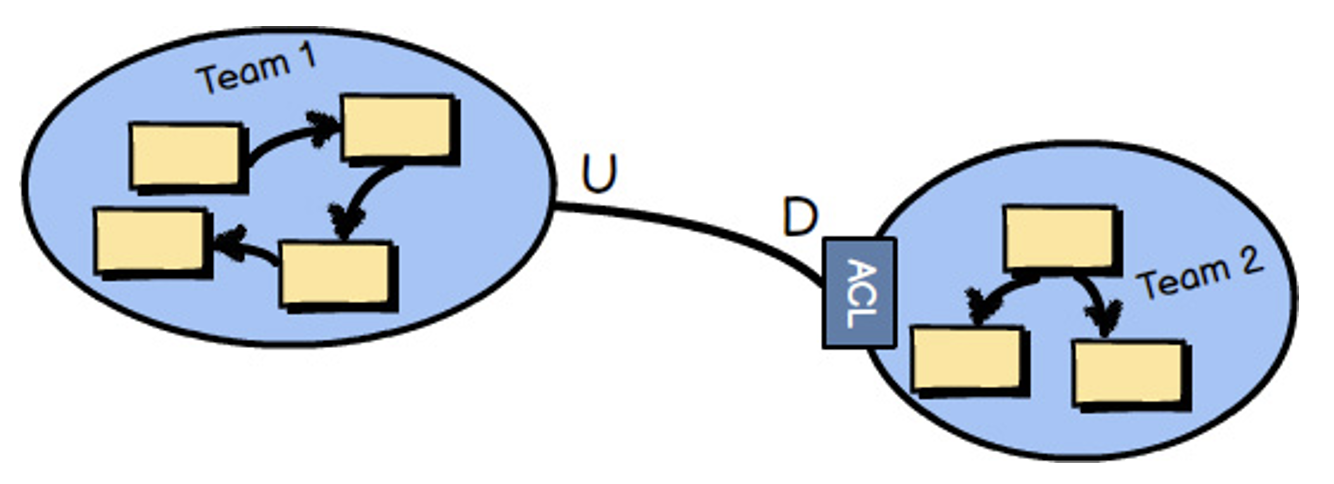
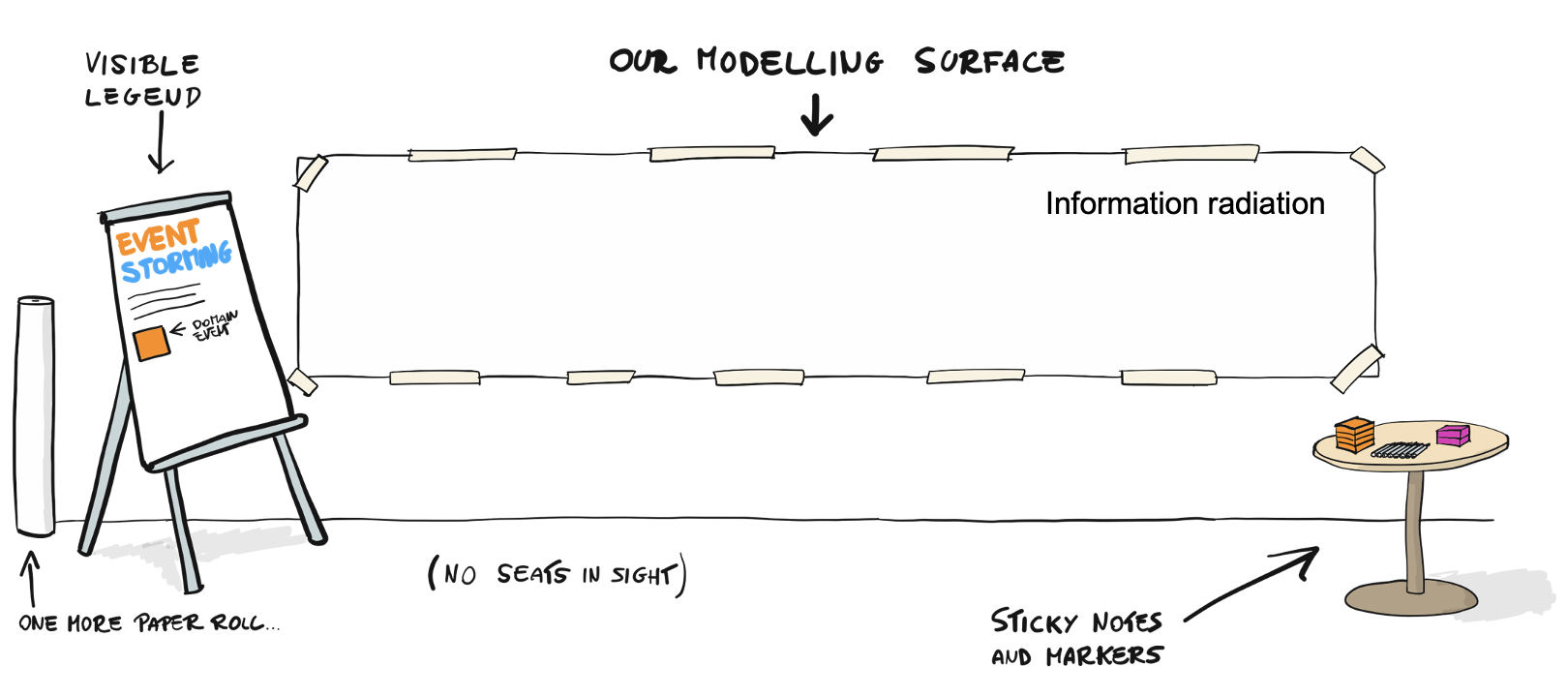
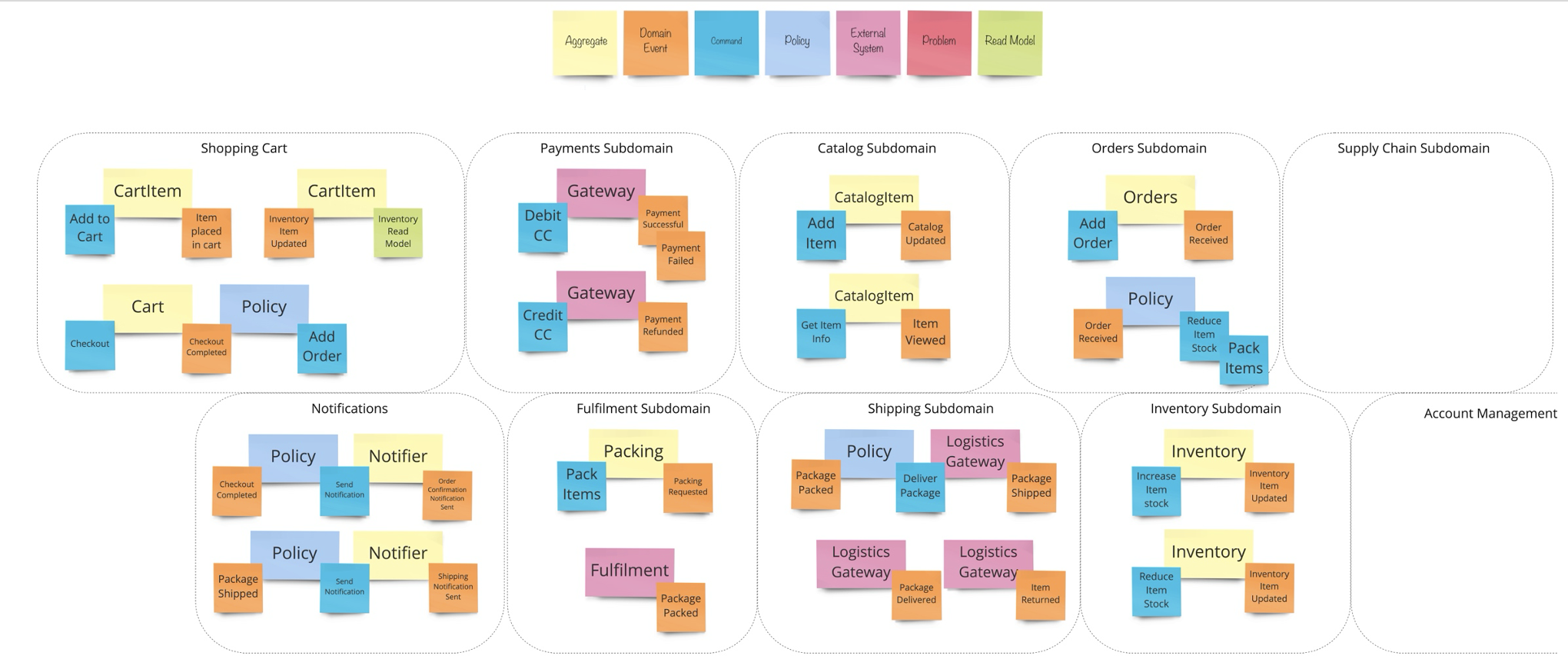
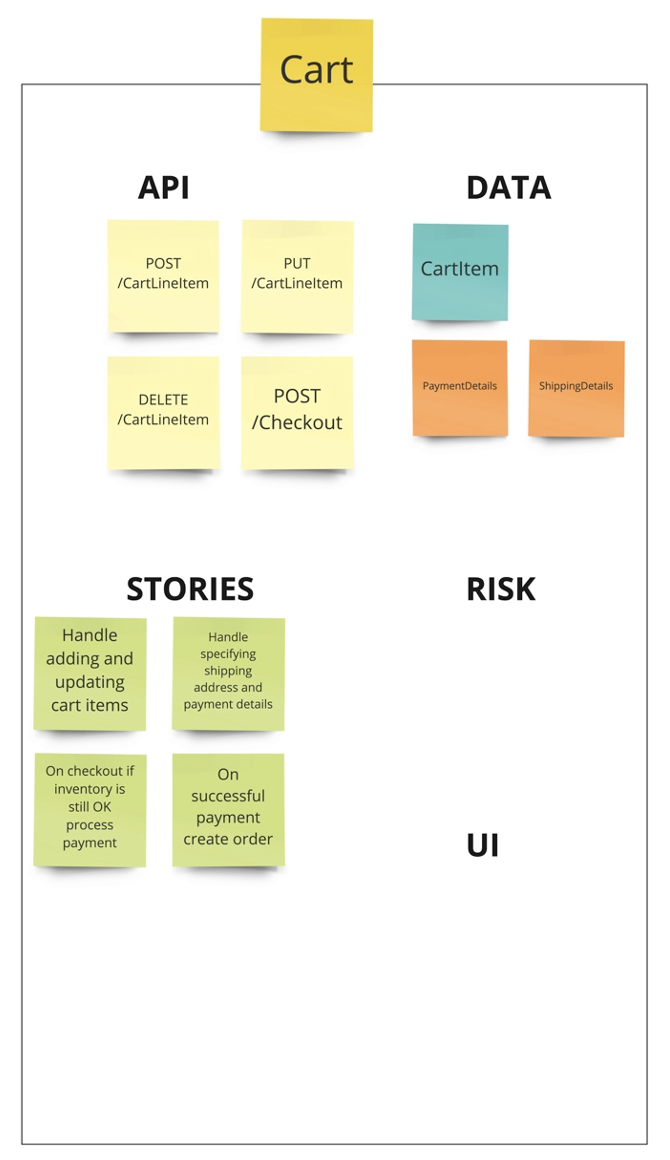
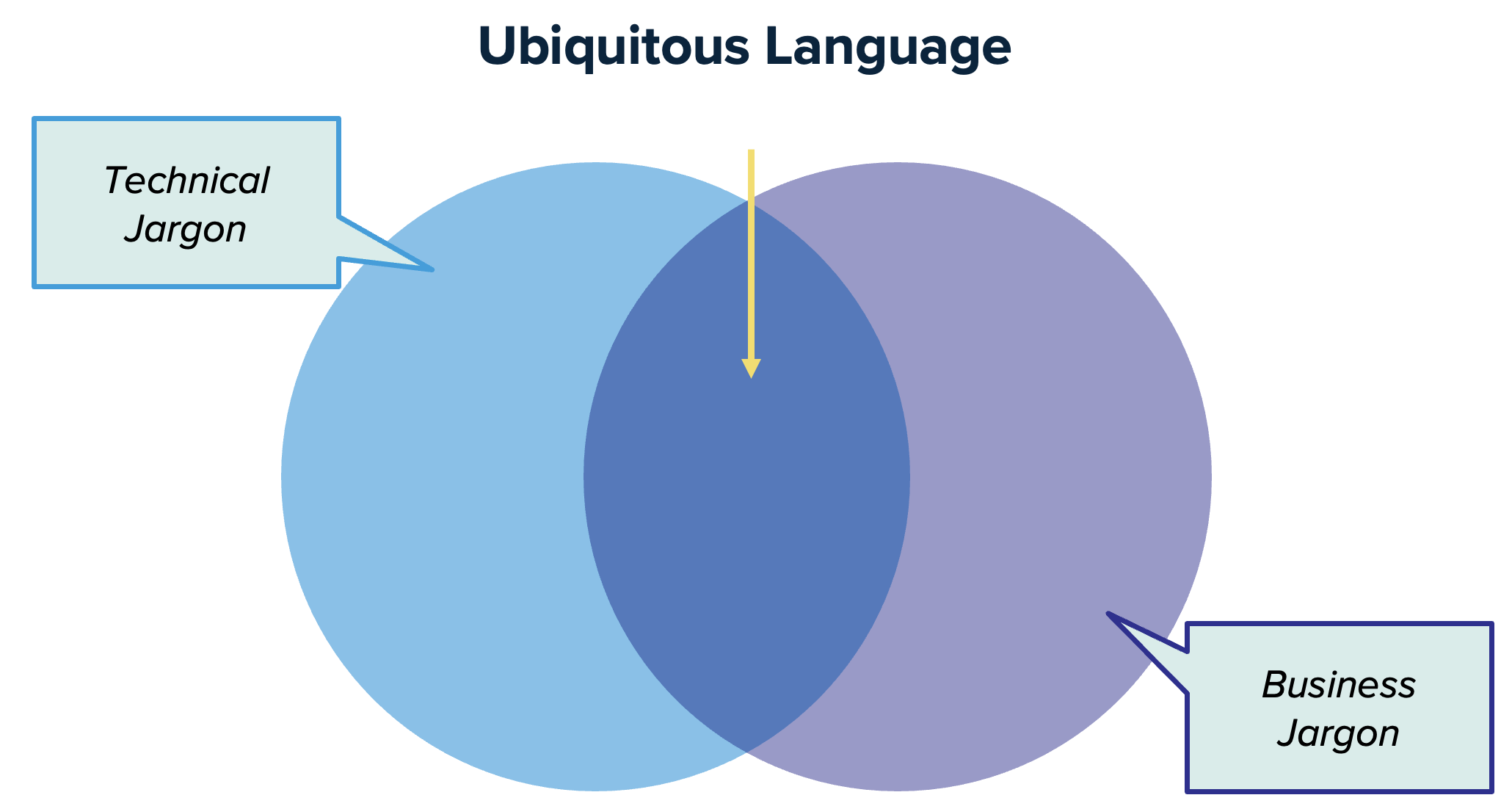
สิ่งสำคัญต่อมาคือการพัฒนาการสื่อสารที่เป็น common language ระหว่าง Business และ IT เพราะปัญหาของนักพัฒนา Application ส่วนใหญ่จะเป็นเรื่องของความเข้าใจที่คลาดเคลื่อน (misaligned) จากผู้ที่เป็น Business หรือเจ้าของ Project (Domain Experts) เพราะคนกลุ่มนี้จะไม่ค่อยเข้าใจเรื่อง IT ดังนั้น Software Developer จะต้องใช้ภาษาที่ Business เข้าใจง่าย รวมถึงการออกแบบจะต้องใช้รูปแบบที่แสดงให้เห็นถึงสิ่งที่เกิดขึ้นในชีวิตจริง จึงจะสามารถพัฒนา Code ตาม Business Concept ได้อย่างถูกต้อง
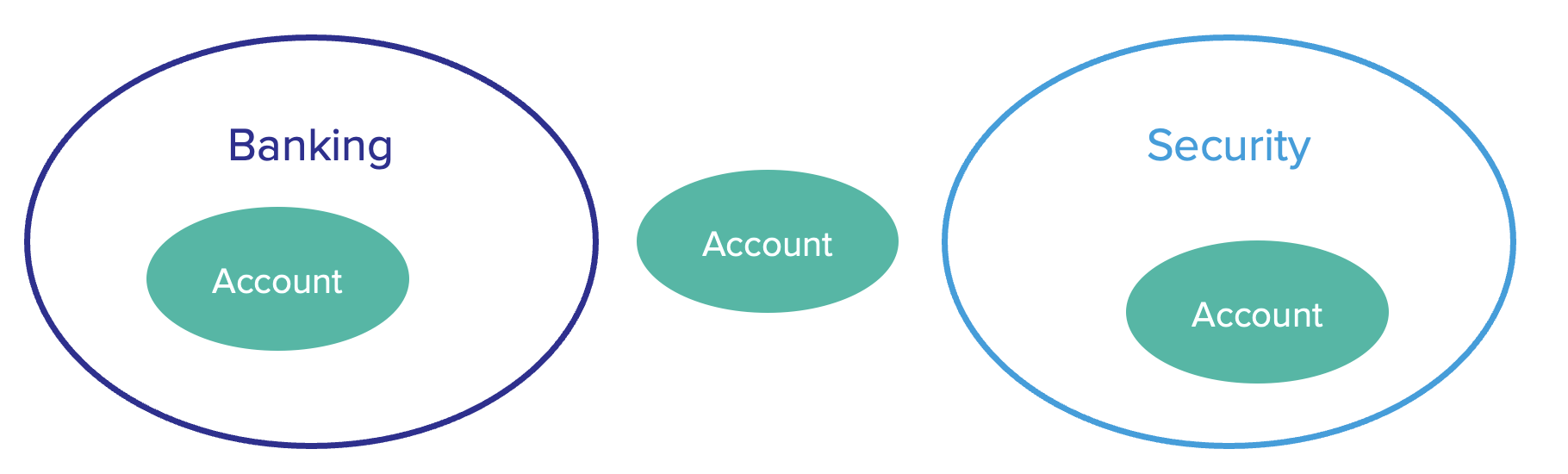
ซึ่งก็คือการใช้ ubiquitous language หรือที่เรียกว่าการใช้ภาษาเดียวกันภายใน bounded context ที่ทีมได้ร่วมกันพัฒนาอยู่
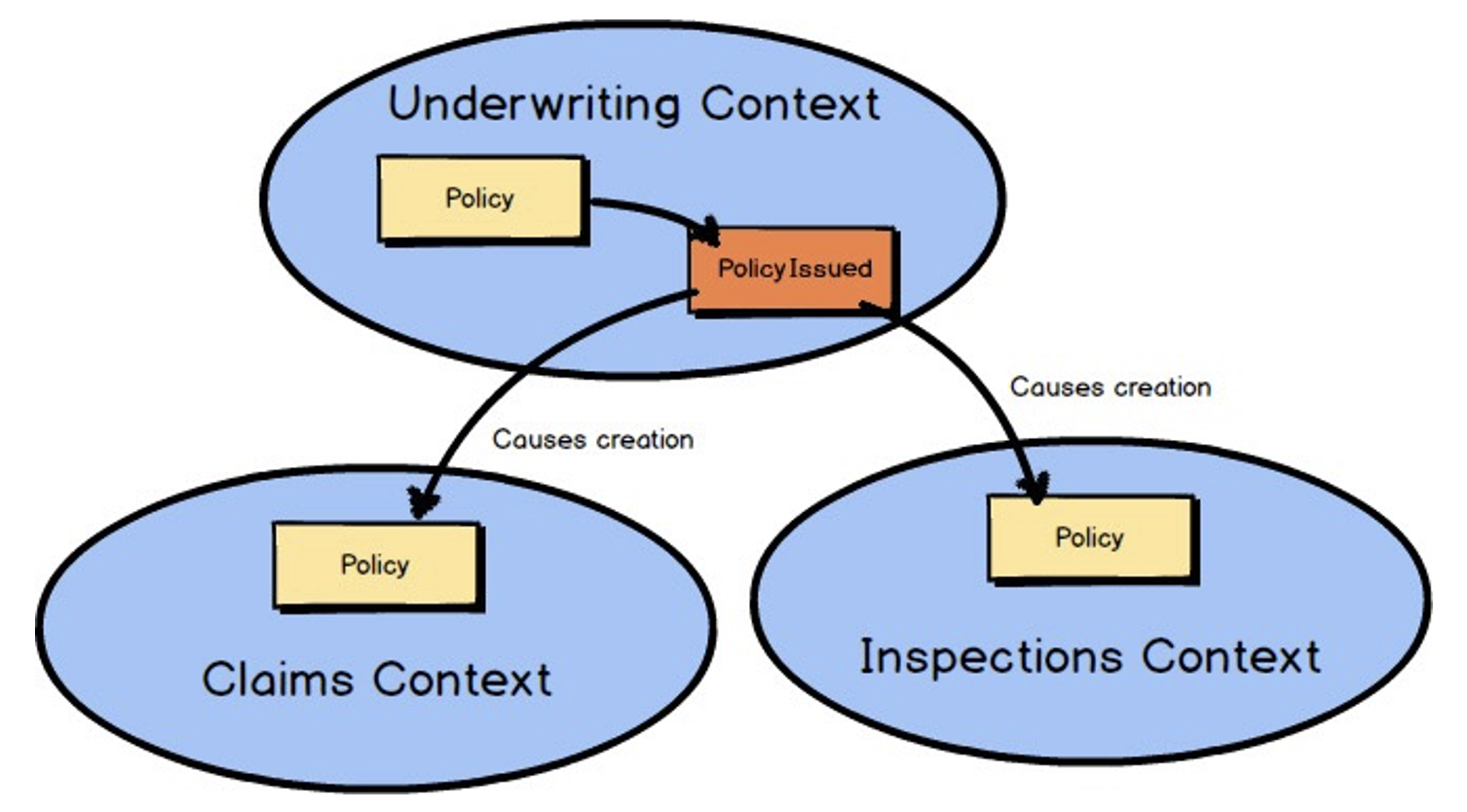
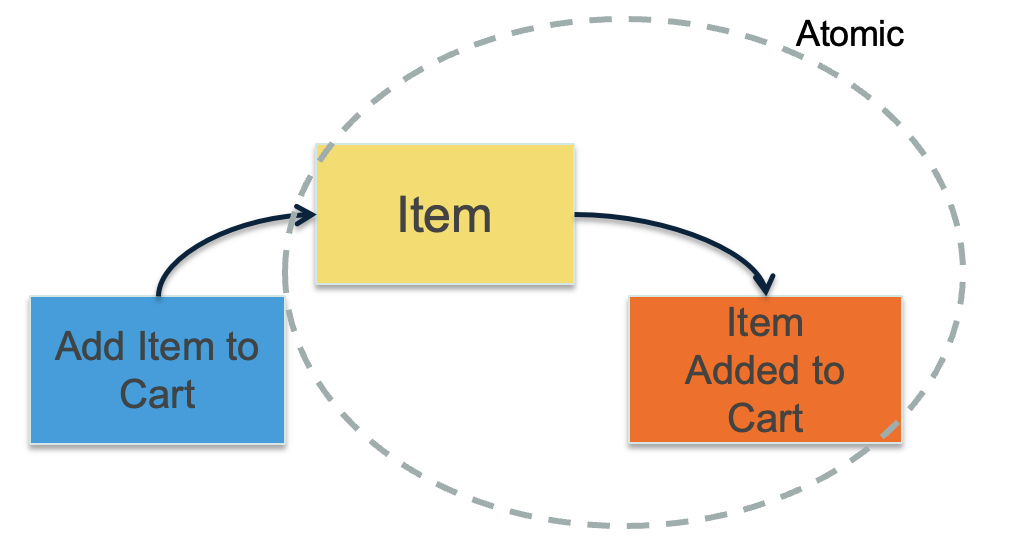
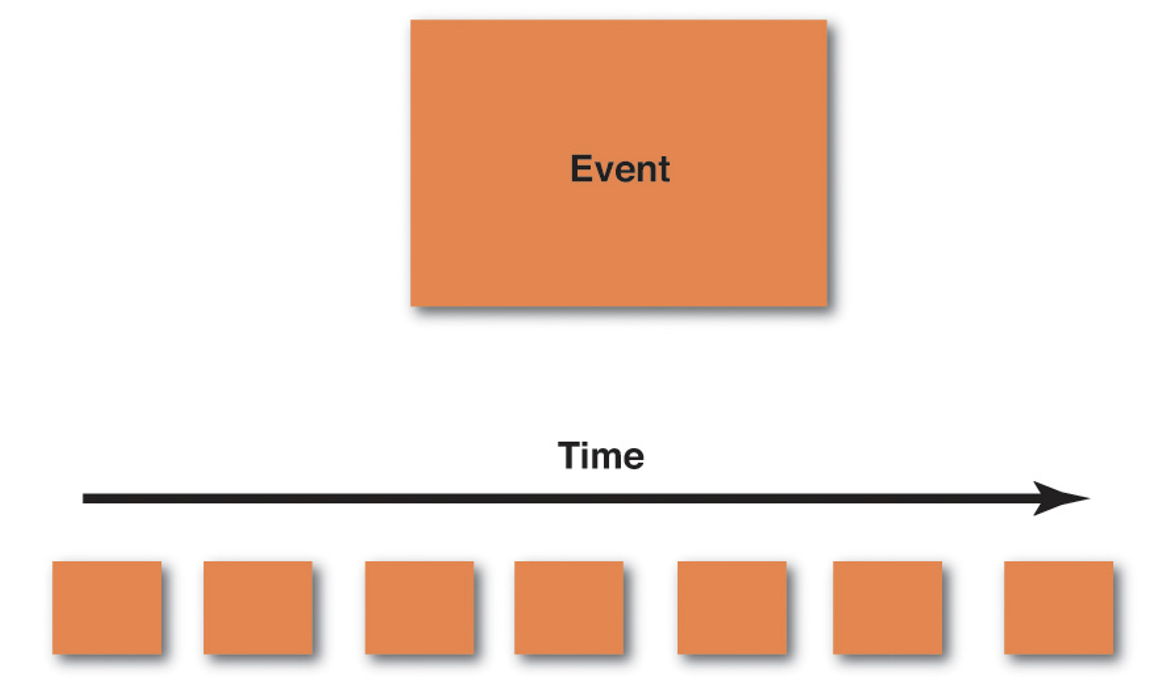
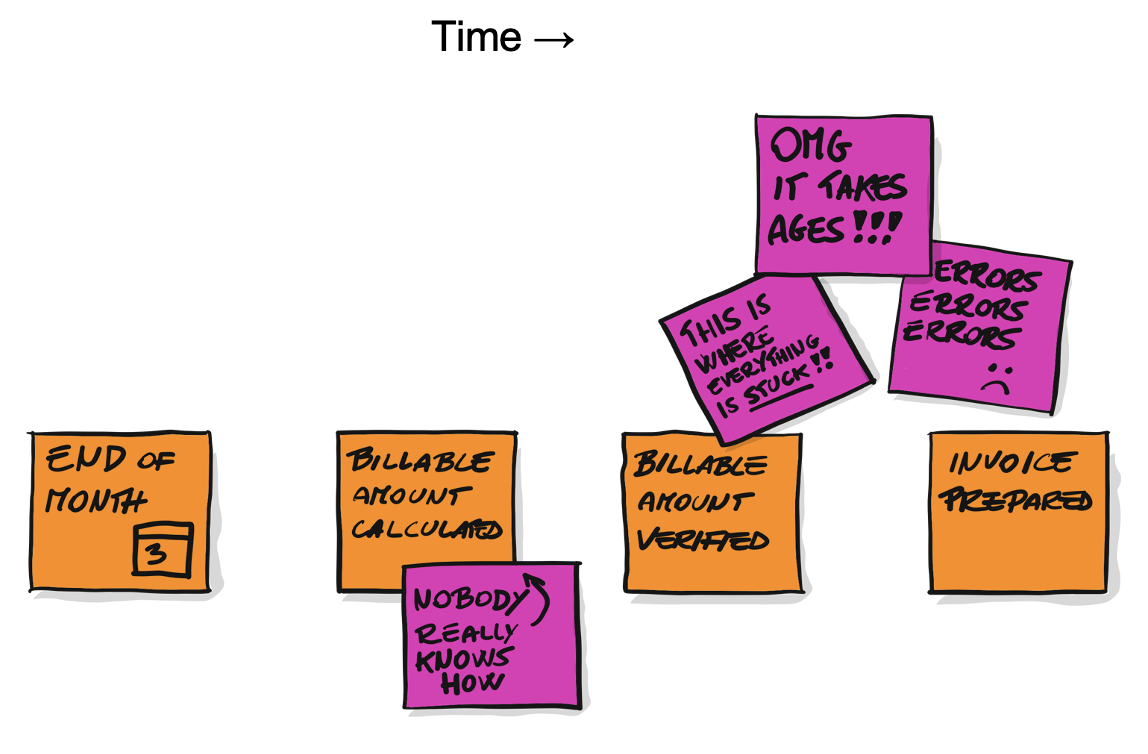
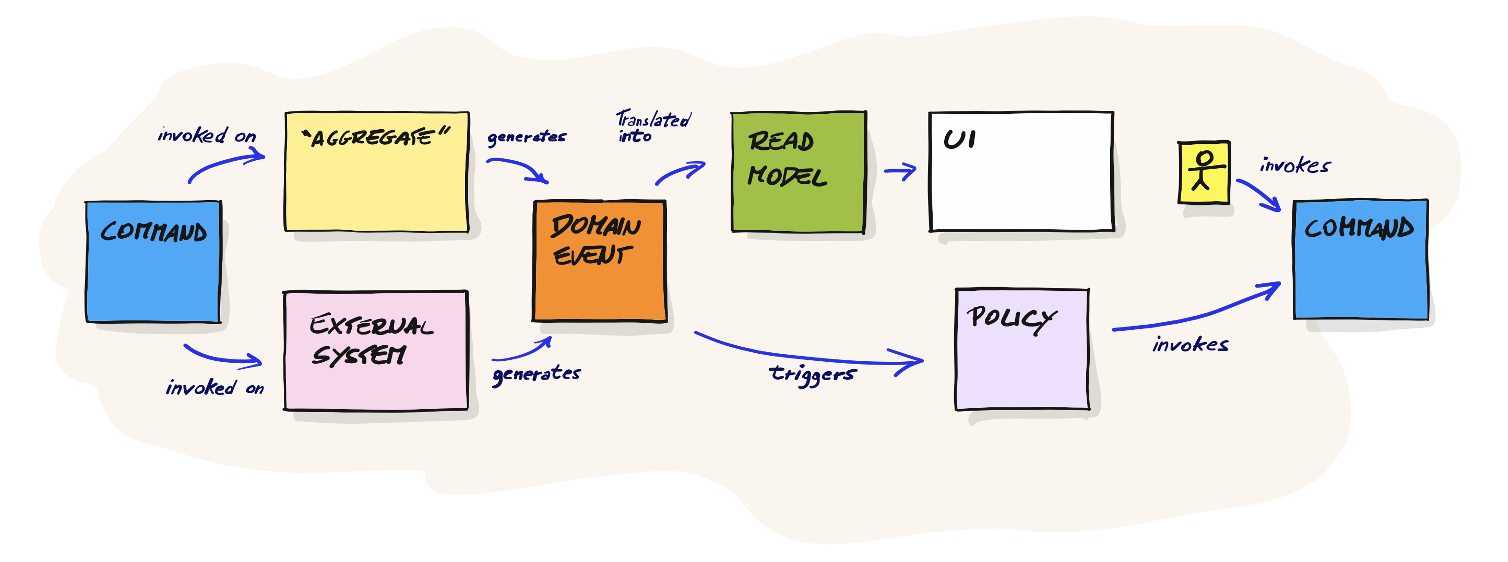
ในการออกแบบ software ควรต้องเริ่มต้นจาก events ที่เกิดขึ้นในแต่ละ business โดย event เองเป็น common language ที่ทั้ง business และ IT สามารถสื่อสารและเข้าใจกันได้ง่าย
เก็บข้อมูลของแต่ละ session (pg_stat_activty) และการทำงานของแต่ละ table (pg_stat_all_tables) และข้อมูล stat ของ database
Backend Process เป็น process ที่จัดการเกี่ยวกับ query ของ user process และส่ง result ที่ได้จาก query จำนวน process ที่จะรองรับ user request จะถูกกำหนดในค่า max_connection ซึ่งมีค่า default ที่ 100 connection ในการ query แต่ละครั้งจำเป็นต้องใช้ local memory โดยมี parameter หลักๆ คือ
Client procces คือ background process ที่ assign ให้กับทุกๆ backend user connection โดย Postmaster process จะสร้าง process ลูกเพื่อให้บริการสำหรับแต่ละ user connection โดยเฉพาะ
SELECT c.relname,
pg_size_pretty(count(*) * 8192) as buffered, round(100.0 * count(*) / (SELECT setting FROM pg_settings WHERE name='shared_buffers')::integer,1) AS buffers_percent,
round(100.0 * count(*) * 8192 / pg_relation_size(c.oid),1) AS percent_of_relation,
round(100.0 * count(*) * 8192 / pg_table_size(c.oid),1) AS percent_of_table
FROM pg_class c
INNER JOIN pg_buffercache b
ON b.relfilenode = c.relfilenode
INNER JOIN pg_database d
ON (b.reldatabase = d.oid AND d.datname = current_database())
GROUP BY c.oid,c.relname
ORDER BY 3 DESC
LIMIT 10;
Query เพื่อหา waiting หรือ block
SELECT * FROM pg_stat_activity
WHERE wait_event IS NOT NULL AND backend_type = 'client backend';
กรณีที่ query ถูก block จาก connection อื่น ใน Postgresql 9.6 ขึ้นไป ใช้ function pg_blocking_pids() เพื่อให้ได้ process ID ที่ถูก block แล้วค่อยหา statistic
SELECT * FROM pg_stat_activity
WHERE pid IN (SELECT pg_blocking_pids())
Query statistic ของแต่ละ type
select query, calls, total_exec_time, min_exec_time, max_exec_time, mean_exec_time, stddev_exec_time, rows
from public.pg_stat_statements order by total_exec_time desc;
Query แสดง statistic ของ sequential scan
SELECT schemaname, relname, seq_scan, seq_tup_read, idx_scan, seq_tup_read / seq_scan AS avg
FROM pg_stat_user_tables
WHERE seq_scan > 0
ORDER BY seq_tup_read DESC;SELECT schemaname, relname, seq_scan, seq_tup_read, idx_scan, seq_tup_read / seq_scan AS avg
FROM pg_stat_user_tables
WHERE seq_scan > 0
ORDER BY seq_tup_read DESC;
Query แสดงเวลารวม และเวลาเฉลี่ย
SELECT query, total_exec_time, calls, mean_exec_time
FROM pg_stat_statements
ORDER BY total_exec_time DESC;
SELECT *, pg_size_pretty(total_bytes) AS total
, pg_size_pretty(index_bytes) AS INDEX
, pg_size_pretty(toast_bytes) AS toast
, pg_size_pretty(table_bytes) AS TABLE
, (toast_bytes * 100)/NULLIF(table_bytes,0) as toast_percent
FROM (
SELECT *, total_bytes-index_bytes-COALESCE(toast_bytes,0) AS table_bytes FROM (
SELECT c.oid,nspname AS table_schema, relname AS TABLE_NAME
, c.reltuples AS row_estimate
, pg_total_relation_size(c.oid) AS total_bytes
, pg_indexes_size(c.oid) AS index_bytes
, pg_total_relation_size(reltoastrelid) AS toast_bytes
FROM pg_class c
LEFT JOIN pg_namespace n ON n.oid = c.relnamespace
WHERE relkind = 'r'
) a
) a
where table_schema = 'public'
order by table_bytes desc;
Query จำนวน live, dead rows และ last vacuum
SELECT schemaname, relname, n_live_tup, n_dead_tup, (n_dead_tup * 100)/(NULLIF(n_live_tup, 0)) as dead_tup_percent, last_autovacuum, last_vacuum FROM pg_stat_all_tables
where schemaname = 'pg_toast' or schemaname = 'public'
ORDER BY n_live_tup DESC
LIMIT 20;
SELECT datname, usename, pid, current_timestamp - xact_start AS xact_runtime, state, query
FROM pg_stat_activity
WHERE query LIKE '%autovacuum%' AND query NOT LIKE '%pg_stat_activity%'
ORDER BY xact_start;
SELECT left(query, 100) AS short_query,
round(total_time::numeric, 2) AS "total_time (msecs)",
calls,
round(mean_time::numeric, 2) AS "mean_time (msecs)",
round(stddev_time::numeric, 2) AS "stddev_time (msecs)",
round((100 * total_time / sum(total_time::numeric) OVER ())::numeric, 2) AS percentage_cpu
FROM pg_stat_statements
ORDER BY total_time DESC
LIMIT 20;