คือจำนวนของ Pod ซึ่งเป็น deployable unit (containers) ที่สามารถทำงานได้ต่อหนึ่งเครื่อง (Node) โดยเราต้องมีข้อมูล
vCPU ที่ pod ใช้งาน อาจจะใช้ cpu limit (ปกติจะต้องทำ cpu limit ไว้ เพื่อไม่ให้ pod ใช้ cpu ของเครื่องหมดจนส่งผลกระทบทั้ง cluster)
vCPU ของเครื่อง (Node) สำหรับใช้ในการ run pod
vCPU ทั้งหมดของเครื่อง (Node)
เปอร์เซ็นต์ของ cpu ที่จะ reserve ไว้สำหรับงานอื่นๆ เช่น system process
จากนั้นก็จะสามารถหาค่า pod per node density ได้จากการหาว่ามี vCPU สำหรับใช้ได้จริงเท่าไหร่ แล้ว หารด้วยค่าเฉลี่ยของ vCPU ที่ pod ใช้งาน เช่น
Node VM มี 8 vCPU และต้องการ reserve vCPU ไว้ 15% สำหรับ system process โดยค่าเฉลี่ยที่ pod ใช้งาน cpu core คือ 0.2 vCPU ต่อ Pod ก็จะหา pod per node density ได้ดังนี้
vCPU ที่ใช้งานได้ = 8 – (8*15/100) = 6.8 vCPU
Pod per node density = 6.8/0.2 = 34
** การกำหนดค่าเฉลี่ย vCPU ที่ pod ใช้งาน ต้องพิจารณา pods per CPU core จากคำแนะนำของ Kubernetes ที่ 1 CPU core จะสามารถรองรับได้ที่มากที่สุด 10 pods และจำนวน pod ต่อ Node ไม่ควรเกิน 110 pods – https://kubernetes.io/docs/setup/best-practices/cluster-large/
ทำให้ pod per node density เพิ่มขึ้นเป็น = 100/4 = 25
หลังจากได้ pods per node density แล้วต้องคำนวณด้วย cpu core ที่ pod ใช้งานถึงจะ sizing ขนาดของ node ได้ว่าจะต้องเผื่อ cpu และ memory ไว้ที่เท่าไหร่ถึงจะเหมาะสม
หลักการที่เรามีแค่เหตุผลเดียวในการสร้าง class ขึ้นมาเพื่อทำงานใดงานหนึ่ง ไม่ควรให้ class ที่สร้างขึ้นมาทำงานหลายหน้าที่ (responsibility) เช่นออกแบบ class เพื่อหาพื้นที่รวมของรูปทรงต่างๆ ก็ไม่ควรให้ class นี้จะต้องทำเรื่องการแสดงผล (output format) ที่ได้ออกมาในรูป html หรือ json เพราะจะทำให้ class นี้ถูกสร้างขึ้นมาด้วยเหตุผลมากกว่าหนึ่งเหตุผล หรือถูกใช้หรือ support เฉพาะบางกลุ่มหรือบาง role
Object หรือ entities ต้องสามารถ extend ได้ แต่ต้องแก้ไขไม่ได้ เป็นหลักการที่ทำให้โครงสร้างของ code เดิมไม่กระทบเมื่อมี type หรือ object ที่แตกต่างออกไป เช่น การที่เรามี class สำหรับรวมพื้นรวมของรูปทรงสี่เหลี่ยม กับวงกลม ด้วย method sum() ถ้าเรามีสามเหลี่ยมเพิ่มขึ้นมาก็จะหลีกเลี่ยงการแก้ไข method เดิมไม่ได้ เราสามารถแก้ไขได้ด้วยการสร้าง interface shape โดยให้ type object ใดๆ สามารถ extend ไปเพื่อ implement logic หา area ตัวเอง ก็จะทำให้ mothod sum() ของเราก็ไม่ต้องแก้ไขอะไร เพื่อที่จะ support รูปทรงใหม่ๆ
interface ShapeInterface
{
public function area();
}
class Square implements ShapeInterface
{
// ...
}
class Circle implements ShapeInterface
{
// ...
}
class AreaCalculator
{
// ...
public function sum()
{
foreach ($this->shapes as $shape) {
if (is_a($shape, 'ShapeInterface')) {
$area[] = $shape->area();
continue;
}
throw new AreaCalculatorInvalidShapeException();
}
return array_sum($area);
}
}
เป็นหลักการที่ object ของ supper class จะต้องสามารถแทนทีด้วย object ของ subclass ได้โดยที่ต้องไม่ส่งผลต่อ program และ object ของ subclass จะต้องสามารถ access ทุก method และ property ของ super class
public interface Bird{
public void fly();
public void walk();
}
public class Parrot implements Bird{
public void fly(){ // to do}
public void walk(){ // to do }
}// ok
public class Penguin implements Bird{
public void fly(){ // to do }
public void walk(){ // to do }
} // it's break the principle of LSP. Penguin can not fly.
public interface Bird{
// to do;
}
public interface FlyingBird extends Bird{
public void fly(){}
}
public interface WalkingBird extends Bird{
public void work(){}
}
public class Parrot implements FlyingBird, WalkingBird {
public void fly(){ // to do}
public void walk(){ // to do }
}
public class Penguin implements WalkingBird{
public void walk(){ // to do }
ถ้าเปลี่ยนใหม่ให้ penguin สือทอดจาก walkingbird ก็จะทำให้ถูกต้องตามหลักการ และไม่ส่งผมต่อ program ทำให้เกิด bug
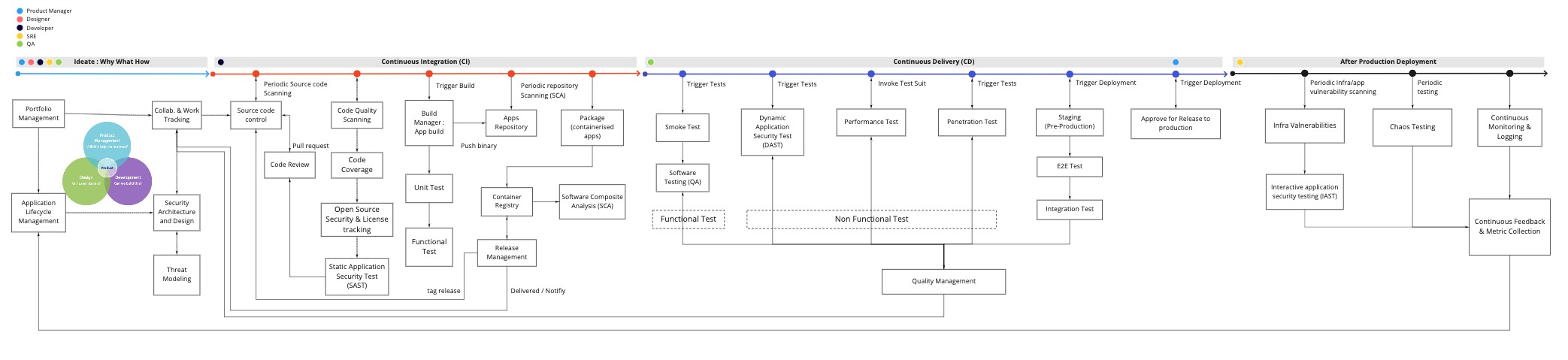
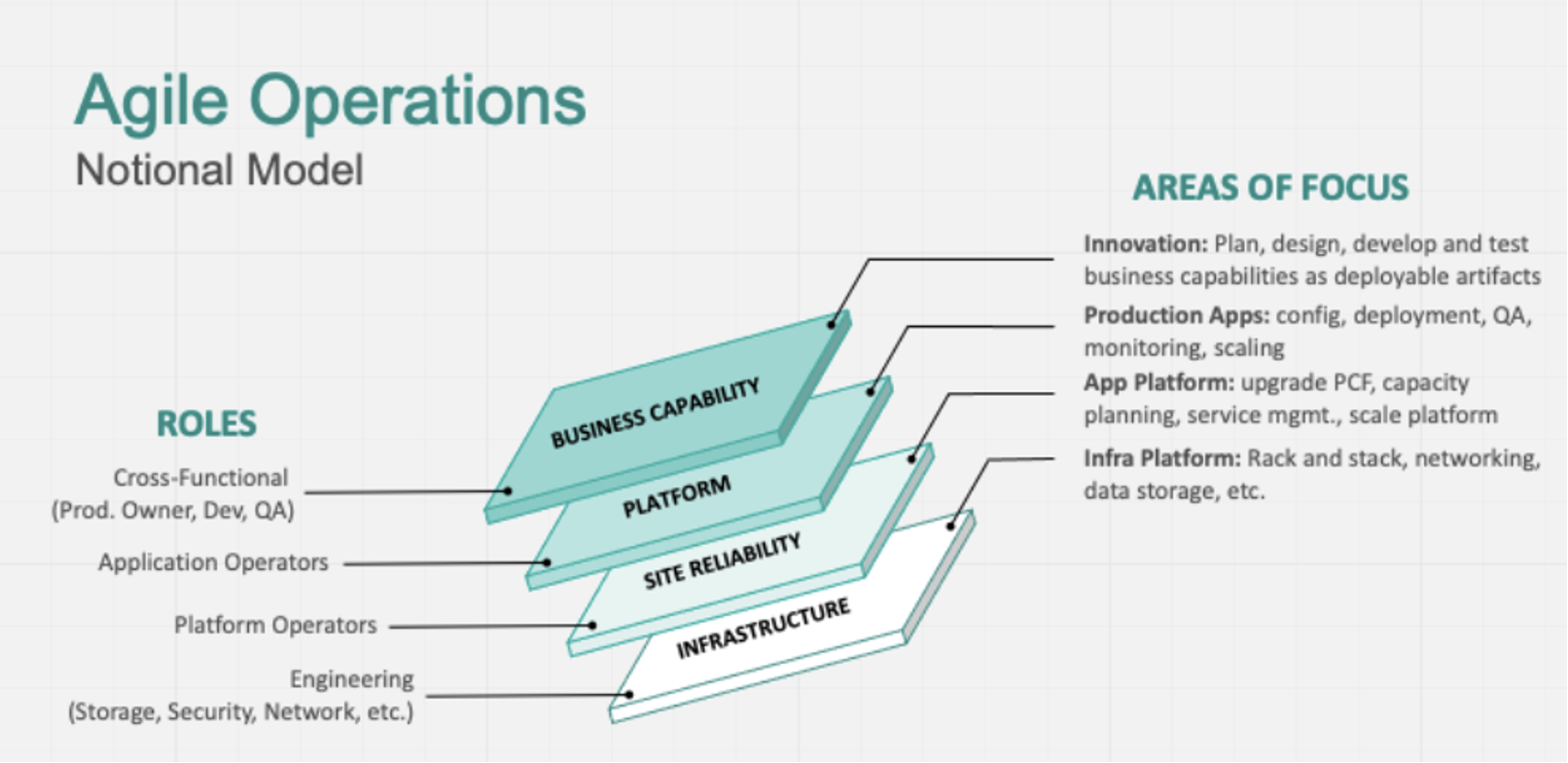
รูปแบบการจัดการทีมงาน เมื่อต้องรองรับการทำงานแบบ agile บางครั้งจะมองว่าเป็นเรื่องของทีม development ที่จริงแล้วต้องมองภาพรวมของทั้ง IT จึงจะสามารถขับเคลื่อนได้อย่างมีประสิทธิภาพ
ด้วยการแบ่ง Roles และสิ่งที่ต้อง focus ในแต่ละ layers ของ IT landscape คือ
Business Capability ต้องมี product team ที่จัดการในลักษณะ cross-functional โดยประกอบด้วย product owner, designer, dev, QA รับผิดชอบในการ develop application ตลอด life cycle เช่น plan, design, develop และ test
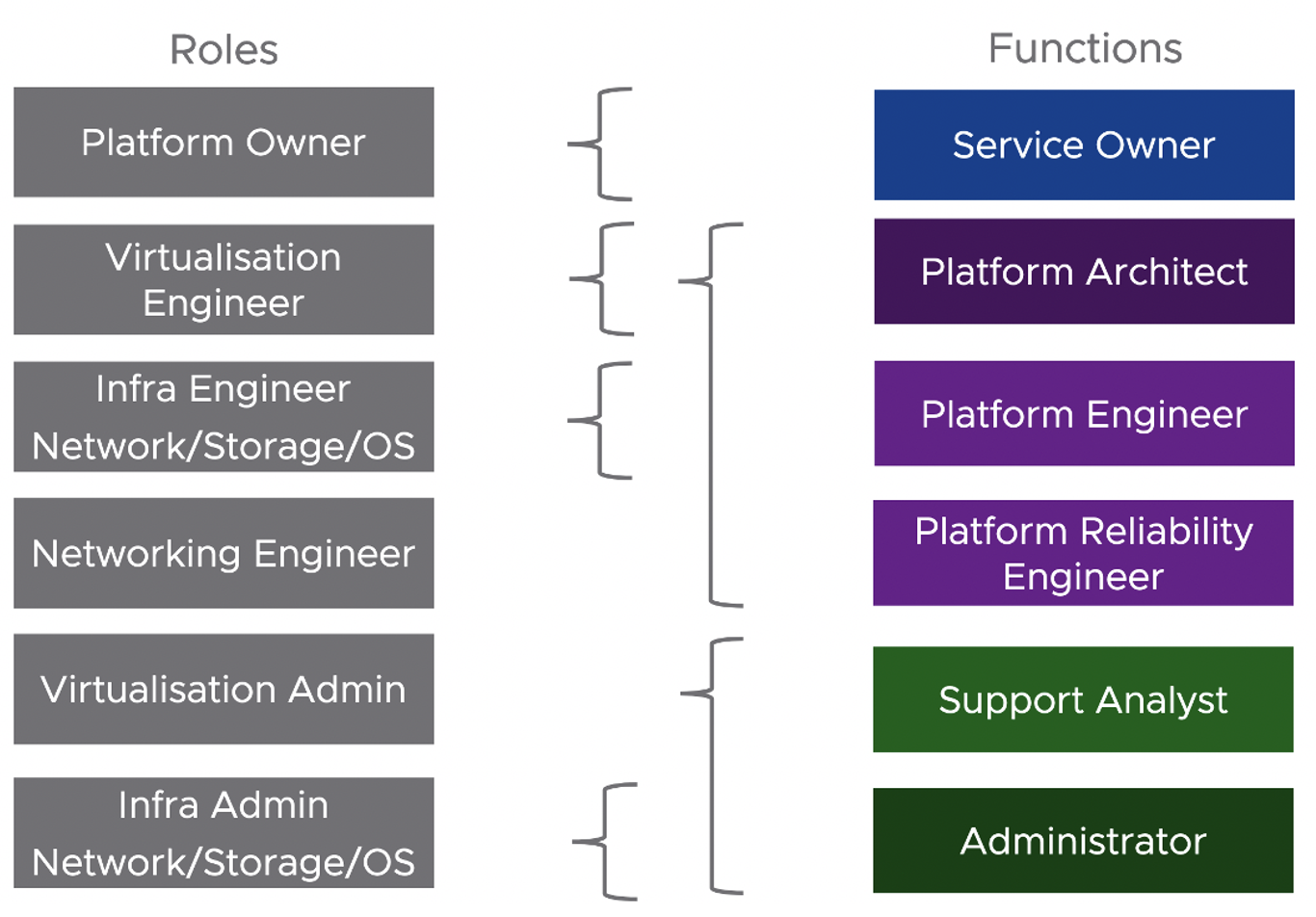
แต่ถ้าเราจะมองในมุม functional ของงานและแบ่งแยกย่อยลงไปอีกก็สามารถใช้รูปแบบนี้เป็น model ก็ได้เช่นกัน
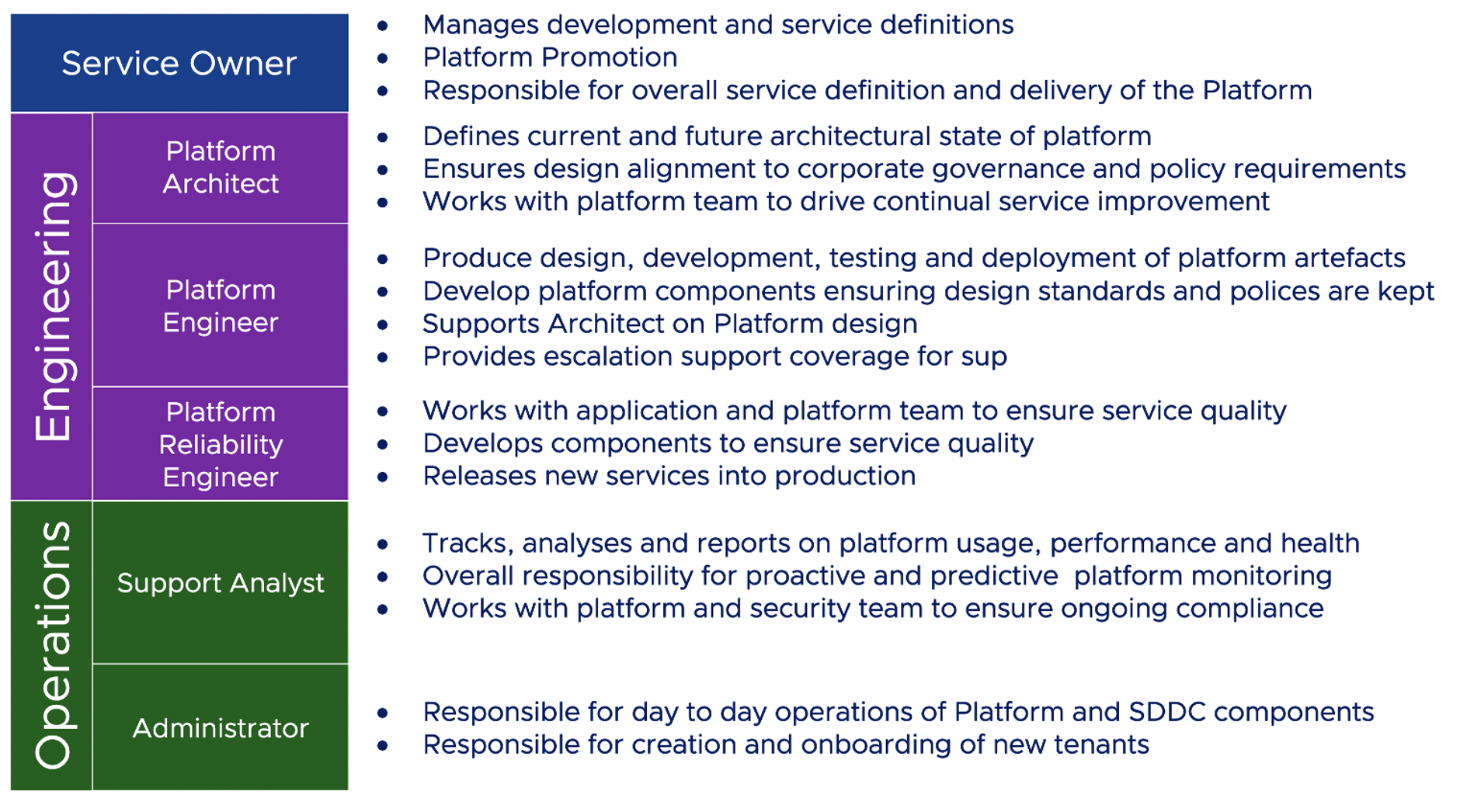
และเมื่อ map role กับ functions งานก็จะได้ดังรูป
การจะเลือกรูปแบบใดนั้นขึ้นอยู่กับความซับซ้อน และขนาดของระบบที่แต่ละองค์กรมีความแตกต่างกัน ดังนั้น role ของ IT ในแต่ละองค์กรจึงไม่จำเป็นต้องเหมือนกันทุกองค์กร
Source code จะต้องถูกจัดการผ่าน Gitlab หรือ git version control รวมถึง Infra code หรือ technical code อื่นๆ เป็นการจัดการ code ที่เดียวเพื่อความชื่อถือและถูกต้องเสมอสำหรับ development team (one source of truth) โดยมีหลักพิจารณาคือ
Trunk Based Development เป็นการให้ engineer ทำงานอยู่บน development branch (main branch) ในระยะเวลาที่สั้น (short iterations) ดีกว่าให้มีหลายๆ release หรือ feature branch เพื่อลดปัญหาเรื่องความซับซ้อนและยากลำบากในการ merge code (merge conflicts)
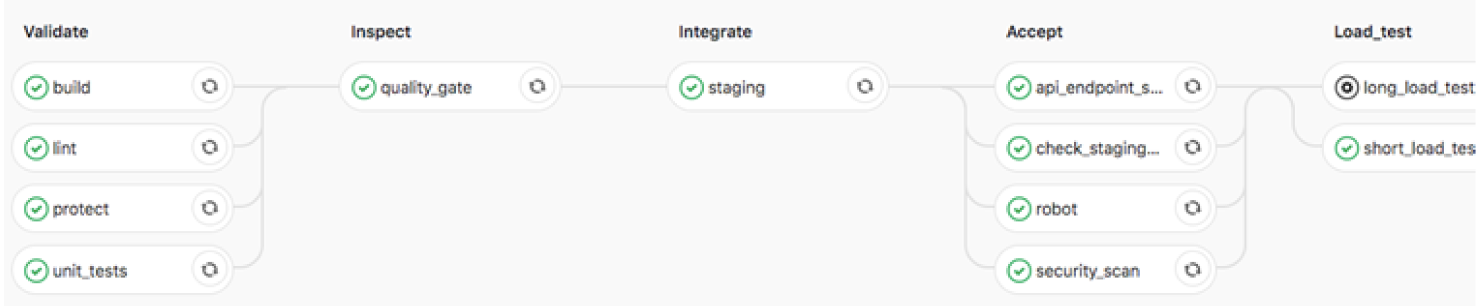
ทำการ automate test ในทุกระดับทั้งที่เป็น functional และ non-functional โดยเลือกใช้ tool ที่เหมาะสมในแต่ละ test case การใช้ automate test tool จะทำให้เห็นปัญหาก่อน User ประกอบด้วย
Unit เป็นการทดสอบส่วนไดๆ ใน code โดยต้องมี coverage ในการ test ที่เหมาะสม
Integration เป็นการทำ end to end test ประกอบด้วยการทำ API test และ UI test เพื่อ simulate การใช้งานของ User
Performance เป็นการ load test เพื่อให้มั่นใจว่า application สามารถทำงานได้ในภาวะการณ์ต่างๆ ได้ ทั้งกรณีที่มี request และมีการส่ง data (payload) เข้ามามากกว่าปกติ
Security Testing
Web app และ Mobile application จำเป็นต้องมีการตรวจสอบความปลอดภัยมากกว่าเดิม จากการเข้าถึงของผู้ใช้งานได้ทั่วไป ดังนั้นโดยทั่วไปจึงมีการทำ hardening และ end-to-end penetration test จากหน่วยงานภายนอกก่อนที่จะขึ้น production การทำ security testing สามารถทำได้หลายวิธี โดยการทำให้เป็นส่วนหนึ่งของ agile process และ devops